What Makes a Python Open Source Package Healthy? A Conversation on Twitter.
Nov 21, 2022 • Software
How should pyOpenSci measure Python open source package health and level of maintenance and usability? Here I summarize a conversation held on twitter around this very topic. Feedback is welcome!
This blog post is part 3 of a 3 part series on open source package health. The series was inspired by a conversation held on twitter. This blog post is not a comprehensive perspective on what pyOpenSci plans to track as an organization. Rather it’s a summary of thoughts collect during the conversation on twitter that we can use to inform our final metrics.
- In blog 1/3 I discussed why Python open source software matters to scientists (and package maintainers too)
- In blog 2/3 I discussed why free and open source package metrics matter and which categories of metrics we at pyOpenSci are thinking about tracking.
In this post, I’ll summarize a conversation that was held on twitter that gaged what the community thought about metrics to track the health of scientific Python open source packages.
Packages and open source software, a few terms to clarify
- When I say Python package or Python open source software, I’m referring to a tool that anyone can install to use in their Python environment.
- When I say open source or free and open source software I’m referring to Python tools that are free to download and and their code is openly available for anyone to see (open source).
What is package health anyway?
There are many different ways to think about and evaluate open source Python package health.
Below is what I posted on Twitter to spur a conversation about what makes a package healthy. And more specifically what metrics should we (pyOpenSci) collect to evaluate health.
My goal: to see what the community thought about “what constitutes package health”.
controversial topic: How do we measure the "health" of a #science #python package? GitHub stars? downloads, date of latest commit? # of commits a month / quarter? Spread of commits? Thoughts? #opensource #OpenScience @pyOpenSci
— Leah Wasser 🦉 (@LeahAWasser) October 5, 2022
The twitter convo made me realize that there are many different perspectives that we can consider when addressing this question.
More specifically, pyOpenSci is interested in the health of packages that support science. So we may need to build upon existing efforts that have determined what metrics to use to quantify package health and customize them to our needs.
A note about our pyOpenSci packages
pyOpenSci does not focus on foundational scientific Python packages like Xarray Dask, or Pandas. Those packages are stable and already have a large user base and maintenance team. Rather we focus on packages that are higher up in the ecosystem. These packages tend to have smaller user bases, and smaller maintainer teams (or often are maintained by one volunteer person).
Our package maintainers:
- Often don’t have the resources to build community
- Often are keen to build their user base and to contribute to the broader scientific python ecosystem.
Existing efforts on health metrics: Chaoss project and the Software Sustainability Institute (neil)
I’d be remiss if I didn’t mention that there are several projects out there that are deeply evaluating open source package health metrics.
Several people including: Nic Weber, Karthik Ram and Matthew Turk mentioned the value and thought put into the Chaoss project.
Is this something that the @CHAOSSproj work could be specialized and applied to scientific software?
— Matthew Turk (@powersoffour) October 5, 2022
CHAOSS (https://t.co/moiMUeDuS3) has been thinking about this more generally, but it's interesting to think about some of the more "science" aspects.
— Neil P Chue Hong (he/him|they/them) (@npch) October 6, 2022
I've wondered about "frequency of API changes" - for use in research is it healthier to be "stable" or "move fast/break things"?
Not that controversial! Have you looked into the rich body of work that the @CHAOSSproj community has done? Each metric has been explored in great detail
— Karthik Ram (@_inundata) October 6, 2022
The Software Sustainability Institute lead by Neil P Chue Hong has also thought about package health extensively and pulled together some data accordingly. Neil was also a critical guiding member of the earlier pyOpenSci community meetings that were held in 2018.
We also did some initial work on this in 2017 (see slide 12 of this presentation): https://t.co/1F0iMwfT5g
— Neil P Chue Hong (he/him|they/them) (@npch) October 6, 2022
Snyk and security (which aren’t discussed in this post)
One topic that I am not delving into in this post is security issues. Snyk is definitely a leader in this space and was mentioned at least once in the conversation.
Some existing metric examples
Below are some of the metrics that you can easily access via Snyk’s website.
This might be helpful. This website collects various metrics. And here is the example for numpy. https://t.co/YNsRoMgks4
— Kevin Wang (@KevinWangStats) October 6, 2022
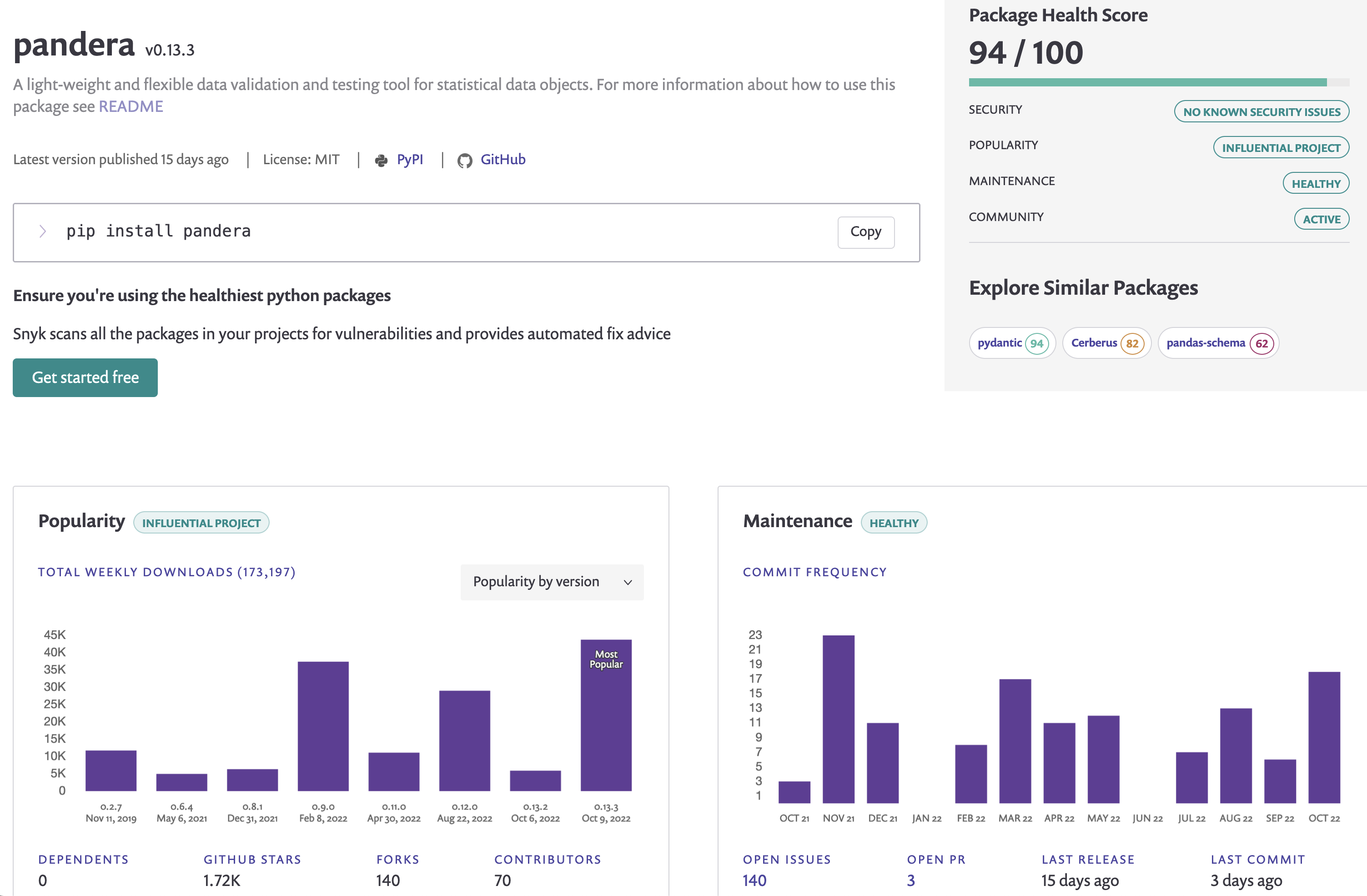
Pandera python package metrics on Snyk
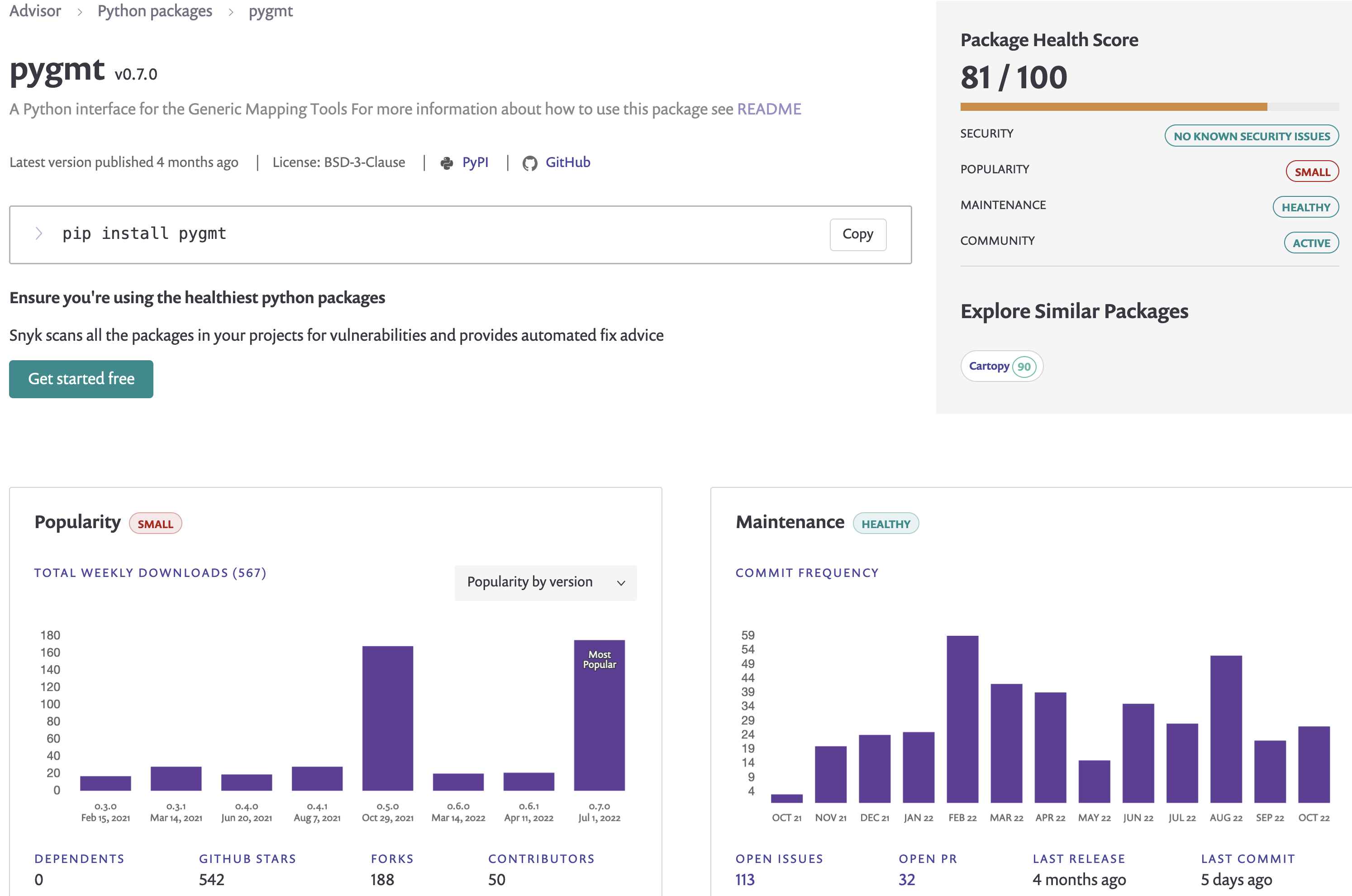
Now let’s look at pyGMT package statistics on Snyk
And of course the scientific Python project has also been tracking the larger packages:
What metrics should pyOpenSci track for their Python scientific open source packages?
So back to the question at hand, what should pyOpenSci be tracking for packages in our ecosystem? Hao Ye (and a few others) nailed it - health metrics are multi-dimensional.
I think, much like "ecological stability" - https://t.co/lJe2Fa0ycR - , "health" here is multi-dimensional and different metrics will capture different facets, such as growth, transparency in governance, stability / backwards compatibility, etc.
— Hao Ye will haunt you for bad keming (@Hao_and_Y) October 5, 2022
I may be a bit biased here considering I have a degree in ecology BUT… I definitely support the ecological perspective always and forever :)
As Justin Kiggins from Napari and CZI points out, metrics are also perspective based. We need to think carefully about the organization’s goals and what we need to measure as a marker of success and as a flag of potential issues.
See insightful thoughts below:
I think that relevant metrics really depend on who is evaluating "health" and what their needs are.
— Justin Kiggins (@neuromusic) October 5, 2022
From UXR work led by @ObusLucy, we found that what users of open source bioimaging plugins are looking for depends on whether they are looking at plugins for general purpose analyses or niche/emerging analyses.
— Justin Kiggins (@neuromusic) October 5, 2022
In the former case, they look for signals of usage (downloads, citations) and in the latter, signals of maintenance and support (commits, comments by dev on issues, etc).
— Justin Kiggins (@neuromusic) October 5, 2022
I suspect this is different from what a funder who is interested in sustainability or a corporation who is interested in their software supply chain would look for to define "health"
— Justin Kiggins (@neuromusic) October 5, 2022
Alas it is true that metrics designed for reporting that a funder requires for a grant may differ metrics designed for internal evaluation that informs program development. pyOpenSci has a lot to unpack there over the upcoming months!
Three open source software healthy metric “buckets”
Based on all of the Twitter feedback (below), and what I think might be a start at what pyOpenSci needs, I organized the Twitter conversation into three buckets:
- Infrastructure
- Maintenance
- Community adoption (and usability??)
These three buckets are all priorities of pyOpenSci.
Infrastructure in a Python open source GitHub repository as a measure of package health
So here I start with Python package infrastructure found in a GitHub repository as a preliminary measure of package health. When think of infrastructure I think about the files and “things” available in a repository that support its use. I know that no bucket is perfectly isolated from the others but i’m taking a stab at this here.
git which is a version control system. Version control allows developers to track historical changes to code and files. As a platform built on top of git, GitHub allows developers to communicate openly, review new code changes and update content in a structured way.What does GitHub (and Ivan) think about health checks for Python open source software?
Ivan Ogasawara is a long time advisor, editor and member of the pyOpenSci community. He’s also a generally a great human being who is growing open science efforts such as Open Science Labs; which is a global community devoted to education efforts and tools that support open science.
Ivan was quick to point out some basic metrics offered by GitHub which follow their community standards online guidebook here.
Maybe not totally related, but github has a section called community standards that could be used as reference, for example: https://t.co/wmu1bDdcQR
— XMN (@xmnlab) October 8, 2022
Actually it’s totally related, Ivan! Let’s have a look look at the pyOpenSci contributing-guide GitHub repository to see how we are doing as an organization.
Note that we are missing some important components:
- A code of conduct
- A contributing file that helps people understand how to contribute
- Issue template for people opening issues
- Pull request templates to guide people through opening pull requests
- Repository admins accepting content reporting
Um…. we’ve got some real work to do, y’all on our guides and repos. We need to set a better example here don’t we? We welcome help welcome if you are reading this and wanna contribute. Just sayin…
GitHub bare minimum requirements are a great start!
The GitHub minimum requirements for what a software repository should contain
are a great start towards assessing package health. In fact I’ve created a TODO
to add this url of checks to our pre-submission and submission templates as
these are things we want to see too; and also to update our repos accordingly.
Health check #1: are all GitHub community checks green?
Looking at these checks more closely you can begin to think about different categories of checks that broadly look at package usability (readme, description), community engagement (code of conduct, templates), etc.
The GitHub list includes:
- Description
- README.md file ((but what’s in that))
- Code of conduct (but what’s in that file?!)
- License (OSI approved)
- Issue templates (great for community building)
- Pull request templates
These checks are great but don’t look at content and quality
But these checks don’t look at what’s in that README, or how the issue templates are designed to invite contributions that are useful to the maintainers (and that guide new potential contributors).
In short, GitHub checks are excellent but mostly exterior infrastructure focused. They don’t check content of those files and items.
So what do content checks look like?
As Chris mentions below, things like having a clearly stated goal and intention, likely articulated in the README file is a sign of a healthy project. This goal was ideally developed prior to development beginning. Further, if well-written, it helps keep the scope of the project management.
To this point - i think that an example of a healthy project behavior is that it explicitly states its technical and organizational goals and intentions
— Chris Holdgraf (@choldgraf) October 6, 2022
Test suites and Python versions
Another topic that came up in the discussion was testing and test suites. Evan, who has been helping me improve our website navigation suggested looking at test suites and what version of Python those suites are testing against.
My initial reaction is that it should have to do with the presence and quality of automated tests, and the versions of Python those tests are run against.
— Evan (he/him) (@darth_mall) October 5, 2022
I can imagine a small, mature package needs little more than minor updates to run on newer versions of Python.
Test suites are critical not only to ensure the package functionality works as expected (if tests are designed well). They also make it easier for contributors to check if changes they made to the code in a GitHub pull request don’t break things unexpectedly.
Tests can also be created
in a Continuous Integration (CI) workflow to ensure code syntax is consistent
(e.g. linting tools such as Black) and to test documentation builds for broken
links and other potential errors.
How should pyOpenSci handle Python versions supported in our review process?
In fact the website that you are on RIGHT NOW has a set of checks that run to test links throughout the site and to check for alt tags in support of accessibility (Alt tags support people using screen readers to navigate a website).
Infrastructure: Is it easily installable?
How the package is installed is another critical factor to consider. While
these days most packages do seem to be uploaded to PyPI, some still aren’t. And
there are other package managers to consider too such as Conda.
Lots of thoughts on this... 😂
— Kenneth Hoste (@kehoste) October 6, 2022
One aspect is definitely whether or not the package is published through PyPI, whether it follows standard packaging practices, has a test suite or well documented simple examples of how to use it, etc.
Maintenance activity as a metric of health
The second topic that came up frequently on Twitter was the issue of maintenance.
Jed Brown had some nice overarching insight here for things they look at that are indicators of both maintenance and bus factor (risk factor, mentioned below as a measure of how many people / institutions support maintenance). More people and more institutions equals lower risk, fewer people and fewer institutions supporting the package equates to a higher maintenance risk (or risk of the package becoming a sad orphan with no family to take care of it.
CI (multi-platform, coverage, static analysis), promptness of reviews, number of distinct institutions who have committed in past 6 months, ditto who have reviewed PRs in past 6 months, promptness of reviews, quality of commit messages and PR discussion.
— Jed Brown (@five9a2) October 5, 2022
How many times have you tried to figure out what Python package you should use to process or download data, and you found 4 different packages on PyPI all in varying states of maintenance?
I’ve certainty been there. So has RenéKat it seems:
I look to see if issues are being resolved. If it’s not being maintained I’m not going to waste my time installing it.
— RenéKat (@renekat14) October 5, 2022
It’s true. For a scientist (or anyone) it’s a waste of time to install something that won’t be fixed as bugs arise. It’s also not a good use of their time to have to dig into a package repository to see if it’s being maintained or not.
pyOpenSci does hope to help with this issue through a curated catalog of tools which will be developed over time.
But what constitutes maintenance?
How do we measure degree of maintenance? Number of issues being addressed and closed? Average commits each month, quarter or year?
This could be a relative metrics too. Some package maintainers may spend lots of time on issues or have too many to handle quickly as Melissa points out replying to a comment about evaluating maintenance by looking at issues being closed:
Would that apply to large established projects such as NumPy? My guess is it wouldn't 😉
— Ax=13!!! (@melissawm) October 5, 2022
But alas I think there are ways around that. We can look at commits, pull requests and such just to see if there’s any activity happening in the repository. Or if it’s gone dark (dark referring to no long being maintained, answer to issues, fixing bugs, etc).
Well, one should look beyond the number of open issues. A lot of them get closed very fast, many prs are merged on a short timescale too. So if you go into a well established repo and see larger numbers, those may still be just the leftover corner cases of decades of usage.
— Brigitta Sipőcz (@AstroBrigi) October 5, 2022
Greg, interestingly suggested one might be able to model expected future lifetime of a package based upon current (and past?) GitHub activity.
Would you accept "expected future lifetime of package" (where "lifetime" means "period of active maintenance") as a measure of health? That feels like something a model could plausibly be trained to predict...
— Greg Wilson (@gvwilson) October 5, 2022
Uh oh! But are commits enough, Kurt asks? Is there such a thing as a perfect project?
Could a project with no recent commits be healthy? What if it needed no commits?
— Kurt Schwehr, PhD (@kurtschwehr) October 6, 2022
Koen had a more broadly profound thought that would be ideal to consider when creating a new package; especially a small package that supports specific scientific workflows.
Does it do one thing, well? Really well?
Yes, please.
My experience from R. None apply if packages stick to the Unix philosophy of doing one thing really well. This will lead to packages with considerable uptake but little development. Base code of {snotelr} is mostly unchanged since inception (12K users).https://t.co/3oKwmeBaA8
— Koen Hufkens, PhD (@koen_hufkens) October 5, 2022
While this might be challenging to enforce in peer review, it is a compelling suggestion.
How do developers evaluate package maintenance?
There is a developer perspective to consider here too. Yuvi Panda pointed out a few items that they look for:
- Frequency of merged commits
- Bus factor
- Release cadence (a topic brought up a few times throughout the discussion)
Remember, bus factor has nothing to do with buses, but there is some truth to the analogy of what happens when the wheels fall off.
Without being specific to open science, I always look at: 1. how frequently are commits being merged? 2. what does bus factor look like (is it just 1 person?), 3. What is cadence of release
— Yuvi Panda (@yuvipanda) October 6, 2022
One thought I had here was to look at commits from the maintainer relative to total commits to get a sense of community contribution (if any).
thanks Yuvi! i hadn't heard of the term bus factor before but was thinking that it would be interesting to look at how many commits do NOT belong to the maintainer in a ratio type of form. Since we have the maintainer information from our reviews we could potentially do that.
— Leah Wasser 🦉 (@LeahAWasser) October 6, 2022
The CHAOSS project has an entire working group devoted to risk.
Or perhaps pyOpenSci asks their maintainers what their perceived risk is? IE: how long do you think the package might remain maintained. They will obviously know better than anyone what their funding environment and support it like.
Erik suggested that metrics can be dangerous and somewhat subjective at times. Akin to the whole - maps can lie; data can lie too . Ok it’s our interpretation that is the risk or lie not the data but … you follow me, yea?
Ask developers how comfortable they would be to depend on the package for a new project. I think "health" is largely subjective and I don't trust metrics without context.
— Erik Welch (@eriknwelch) October 5, 2022
Some including Pierre brought up the idea of consistent releases. Not necessarily frequency but just some consistency to demonstrate that the package was being updated.
Yes. Regular releases is a sign of good health. But given the fact that many scientific projects are often maintained by few people I would avoid any normalization. I'm usually super happy with 1 or 2 releases per year.
— Pierre Poulain (@pierrepo) October 5, 2022
Other discussions evolved around semantic versioning and release roadmaps.
Community adoption of an open source Python tool
Community adoption of an scientific Python package was another broad category seen over and over throughout the Twitter conversation.
- How many users are using the tool?
- How many stars does the package have?
- How often is is the package cited?
Is the package cited?
While we’d love to quantify citations, the reality of this is that most people don’t cite software. But some do, and we hope you are one of them!
Citations, naturally! 😉
— Jacob Deppen (@jacob_deppen) October 6, 2022
What about stars (and commits) as a metrics of adoption (and maintenance)?
The tweeter below looks at stars and commit date as signs of community adoption and maintenance.
Derivative of 🌟 with respect to ⏲️ plus date of last commit!!
— MLinHydro (@MLinHydro) October 6, 2022
As Chris Holdgraf mentions below, a package can reach a point where the same type of activity can have varying impacts of perceived level of maintenance. Many users opening issues, can represent community interest and perhaps even community adoption. And massive volumes of unaddressed issues might represent unresponsive maintainers.
Or perhaps the maintainers are just overwhelmed by catastrophic success.
I think a steady stream of issues implies a lot of user interest, though I can tell you from first-hand experience that it does not mean a project is healthy :-)
— Chris Holdgraf (@choldgraf) October 7, 2022
I think it misses one of the most stressful anti-patterns for OS projects: Catastrophic Success
h/t @fperez_org :-D
Yup
it is the equivalent of when a small bakery gets written up in the New York Times, has a huge influx of customers, and collapses under the weight of demand. I think it's an outcome we don't think about enough ahead of time
— Chris Holdgraf (@choldgraf) October 7, 2022
But I need at least 5 (thousand) croissants, now. ANDDDD so does my friend.
Juan agrees that a steady stream of issues suggests adoption. Especially since opening issues on GitHub suggests that the users have some technical literacy.
As others have said, it’s multidimensional, but this article argues that a steady stream of issues = a community of active and engaged users — often somewhat programming-literate since it’s GH. I find that argument compelling.https://t.co/X2vY2QxRfV
— Juan Nunez-Iglesias (@jnuneziglesias) October 7, 2022
Metrics quantifying community around tools
I’d be remiss if i didn’t at least mention that some of the discussion steered towards community around tools. For instance, Evan brought up community governance being a priority.
Governance was another aspect I was going to suggest. The “benevolent dictator for life” model is… risky
— Evan (he/him) (@darth_mall) October 5, 2022
But the reality of our users was summarized well here by Tania. Most scientists developing tools are trying to simplify workflows with repeated code. Workflows that others may be trying to develop to do the same thing. They aren’t necessarily focused on community, at least not yet.
Also note - a lot of folks developing scientific software are more interested in the pragmatic side of open source (i.e availability, making the codebase public and accessible) rather than building a community around it.
— ✨Tania Allard 💀🇲🇽 🇬🇧 she/her (@ixek) October 6, 2022
Further, capturing metrics around community is hard as Melissa points out. Most of the above resources don’t capture these types of items. And also, how would one capture the work on a community manager quantitatively?
Depends on what is "health". Sustainability? Funding? Maintainability? Culture? I think most metrics are proxies to some other thing we want to measure, but are not representative. For ex looking at github, a bunch of the work done by community managers is not captured at all.
— Ax=13!!! (@melissawm) October 5, 2022
Are some things missing here? Yes, of course.
But it’s a great start!
- Some other items that didn’t come up in the conversation included downloads.
- Packages found as dependencies or in environments on GitHub
Joel rightfully noted that my original tweet seemed less concerned with package quality and more concerned with community and use. I think they are right. We are hopeful that peer review metrics and recommended guidelines for packaging will get at package quality.
I guess that depends on whether you're concerned about the quality of the package or the popularity of the package.
— Joel Bennett (@Jaykul) October 5, 2022
Most of your proposed metrics seem to be about size and activity of the COMMUNITY using the package rather than quality or reliability of the package itself.
Summarizing it all will be a WIP (Work In Progress)
There is a lot of work to do in this area. And a lot of work that has already been done to learn from. It’s clear to me that we should start by looking at what’s been done and what people are already collecting in this area. And then customize to our needs.
A few items that stand out to me that we could begin collecting now surrounding package maintenance and community adoption are below. This list will grow but it’s just a start.
Package Maintenance and Community Adoption
- Date of last commit
- Date of last release
- Annual frequency of releases
- Number of open issues / quarter
- Issues opened by maintainers vs non maintainers
- Number of commits made by non maintainers / year
Package quality & infrastructure
- GitHub core checks for README, Contributing guide, etc
- Documentation & associated documentation quality (vignettes and quick start)
- Defined scope and intent of package maintenance
- Testing and CI setup
I will share a more comprehensive list once we pull that together as an organization in another blog post. Stay tuned for more!
Thoughts?
If you have any additional thoughts on this topic or if I missed important parts of the conversation please share in the comment section below.