Jekyll2025-04-29T23:29:31+00:00https://www.pyopensci.org/feed.xmlpyOpenScipyOpenSci's WebsitepyOpenScipyOpenSci Community Call 5 May 2025 @ 10 am Mountain Time: Right Time, Right Community: My OSS Journey2025-04-22T00:00:00+00:002025-04-22T00:00:00+00:00https://www.pyopensci.org/events/community-call-contribute-open-source Join us for a talk on contributing to open source!
Open Source Voices: A community call for learning, sharing, and growing together
We’re kicking off the week with a special Open Source Voices session! Pavithra will share her open source journey and what helped her grow in the open source world.
Right Time, Right Community: My OSS Journey
Pavithra Eswaramoorthy is a Developer Advocate at Quansight, where she works to improve the developer experience and community engagement for several open source projects in the PyData community. She has been involved in the open source community for over five years. Currently, she is part of the core team for the Bokeh visualization library and Nebari (JupyterHub-based data science platform). In her spare time, she enjoys a good book and hot coffee.
All are welcome
We welcome anyone and everyone to join and learn more about contributing to open source. This is a space for learning, questions, and community. Come and listen, get inspired, and meet others learning about open source.
]]>pyOpenSciReaffirming pyOpenSci’s Commitment to Inclusion2025-03-21T00:00:00+00:002025-03-21T00:00:00+00:00https://www.pyopensci.org/blog/pyopensci-commitment-inclusionDuring challenging times, it’s critical to pause and reflect on who we are, what we care about, and why our work matters. Since its inception, pyOpenSci, a global community fiscally sponsored in the U.S., has been committed to actively building an inclusive, welcoming, open source community of practice that supports better, more open science. Our Code of Conduct reinforces our values, as does the thought that we put into the events that we run, the accessible resources that we develop, and the work that we do to make our peer review program inclusive and creating Python software easier.
Today, we celebrate the core values that drive pyOpensci. Today, we reaffirm our long-standing commitment to building an inclusive, open source community and highlight our mission.
pyOpenSci broadens participation in scientific open source by breaking down social and technical barriers.
And this is how we achieve our mission:
We are a community of novice to expert Pythonistas; together, we make creating, finding, sharing, and contributing to reusable code more accessible to everyone everywhere, supporting open science and advancing discovery.
Carving out space for everyone
Creating an inclusive and welcoming space is core to broadening participation in open source and open science.
When people feel supported, they contribute
When knowledge is shared, communities grow and thrive.
Through mentorship, beginner-friendly events, and accessible resources, we actively invite those who might not otherwise see a place for themselves in open source. Our review process includes both developers and those who use the software; here, inclusion ensures that our reviews consider usability and accessibility in addition to the technical nuances of packaging.
Through mentorship and support, we carve out space for new reviewers, which includes those from historically underrepresented backgrounds in open source to contribute to peer review. Similarly, our beginner-friendly lessons and training events are co-developed with beginner-to-expert contributors to ensure the technical concepts are accessible to more people.
Inclusion invites everyone to the table; it creates space for new contributors and supports existing community members. Inclusion creates opportunities for everyone to work together. Together, we share knowledge, shape best practices, and ensure our work serves the broader community.
A blossoming ecosystem of contributors
By breaking down barriers, we create open science on-ramps that help everyone learn, contribute, and grow together. In many ways, open source communities are like thriving gardens—diverse, vibrant, and sustained by many contributors.
The most vibrant and resilient gardens are full of diverse color, texture, and life, attracting pollinators that sustain the whole system. Cultivating diversity builds resilience. Similarly, contributors in our pyOpenSci community come from different backgrounds, identities, and experience levels.
When we make space for all contributors—ensuring they have what they need to grow—our community becomes more resilient as the ecosystem evolves. Scientific discovery happens organically. The more perspectives and experiences we include, the more impactful our work becomes.
Connect with us!
There are lots of ways to get involved if you are interested!
If you read through our lessons and want to suggest changes, open an issue in our lessons repository here
]]>pyOpenSci Executive CouncilContribute to Open Source Software: It’s More Than just Code2025-03-18T00:00:00+00:002025-03-18T00:00:00+00:00https://www.pyopensci.org/blog/contribute-to-open-source-github-lessons-Copy1Beyond code: the social side of open source
When you think about contributing to open source, you might assume the biggest hurdle for newcomers is technical–learning Git, using GitHub, and/or writing code. Most contribute to open source guides focus on technical skills. But for many new contributors, the challenge isn’t only technical—it’s social too.
Receiving open feedback on your contributions in the form of code review, whether code or documentation, creates anxiety for many.
Joining an unfamiliar community: Understanding who to reach out to and how the project operates can feel intimidating.
Understanding unspoken norms: Every project has its own culture, from how discussions happen to how decisions are made. And these norms are not always well-documented.
Building confidence in a new space: Many contributors worry about making mistakes, be it while using GitHub or submitting a Pull Request or even in the content updates themselves.
Navigating constructive feedback – Open source is built on open peer review; however, receiving public feedback on a contribution can be intimidating.
In my 10+ years of building and maintaining software, contributing to projects, and running beginner-friendly sprints, I’ve seen firsthand that communication, collaboration, and project culture are just as—if not more—important than technical skills. I’ve also experienced the imposter syndrome first-hand. I was nervous about my first contributions and wasn’t sure how to start contributing in a meaningful way.
Technical and social skills go hand in hand. Open source communities are most productive when contributors and maintainers recognize this balance between the technical and social skills associated with contributing. In most cases, all of the people involved in the project are volunteers with varying priorities, skillsets, and motivations to participate.
Developing our contribute to open source lessons
This past year, with support from the Better Software for Science (BSSw) Fellowship, I developed lessons shaped by insights gained from the pyOpenSci contributor community. Our lessons are now freely available as open educational resources designed to help contributors and maintainers foster a more welcoming, collaborative and productive open source community.
BSSw is a unique partnership between the National Science Foundation (NSF) and the Department of Energy (DOE) that provides small grants to advocates in the scientific open source space.
A community-driven approach to open source
Over the past two years, pyOpenSci has welcomed over 300 contributors, with more than 120 issues and pull requests submitted during our beginner-friendly sprints. These experiences reinforced what we already knew—technical skills are just one part of people successfully contributing to open source.
Through our sprints, we saw firsthand how clear guidance, supportive communities, and transparent contribution processes helps newcomers gain confidence. Often, they stick around our community after the events. These insights shaped our Contribute to Open Source lessons.
Beyond code: The social skills of open source
Our lessons address both the technical and social aspects of contributing to open source.
For contributors: how to navigate your first contribution
For contributors, we focus on:
Understanding the technical steps surrounding making your first contribution
Signals that tell you that a project welcomes newcomers and,
What to expect as they navigate their first contributions.
A few highlights include:
Get to know a repository: Learn how to look for documentation files like CONTRIBUTING and DEVELOPMENT guides that will become your guiding light in making your first contributions. These files should help you understand whether new contributions are welcome, what the contribution process is, and what types of contributions are welcome.
Find and understand issues: Explore how to search and create GitHub issues as you begin the process of finding a task to work on. Learn how to communicate effectively with maintainers who you may have never interacted with before.
Create effective pull requests: Learn how to open a pull request, write clear pull request messages titles and descriptions. Also, learn how to make the pull request process more efficient by reviewing your own work and linking your PR to an issue to streamline maintainer review.
For Maintainers: Creating a contributor-friendly repository
While these lessons are focused on contributing, we also provide some maintainer tips to help set clear expectations for contributors:
Communicate your availability: Let contributors know if you have time to support them. It’s okay if you’re busy—just set clear expectations!
Provide clear guidelines: Add CODE_OF_CONDUCT, CONTRIBUTING, and DEVELOPMENT files to define what contributions you welcome and how contributors should engage with your project.
Use automation to support contributors: Tools like pre-commit.ci help automate formatting and linting, reducing friction for new contributors.
Co-Creating open source contribution lessons
Our Contribute to Open Source lessons, like all pyOpenSci resources, are co-developed collaboratively. By bringing together contributors with different backgrounds and skill levels, we ensure our materials are clear, accurate, and welcoming.
A diverse contributor base makes our lessons stronger:
Experts provide technical accuracy.
Beginners ensure content is approachable.
Everyone in between help refine and improve the content.
This same community-driven approach shaped our packaging guide, which covers packaging tools and tutorials. Like our lessons, it was co-developed and openly reviewed to ensure accessibility and clarity.
By openly co-developing and refining these resources together, we’re making scientific open source more accessible for everyone.
What’s next? Broadening participation in open source
With PyCon US and SciPy on the horizon, we’re excited to put these lessons into action. At our upcoming sprints, we’ll work together to refine these resources—improving the lessons and packaging guide to make participating open source even more accessible. If you plan to be at either meeting, keep an eye out for pyOpenSci events!
Connect with us!
There are lots of ways to get involved if you are interested!
If you read through our lessons and want to suggest changes, open an issue in our lessons repository here
]]>Leah WasserHow to Secure Your Python Packages When Publishing to PyPI2025-03-13T00:00:00+00:002025-03-13T00:00:00+00:00https://www.pyopensci.org/blog/python-packaging-security-pypiIs your PyPI publication workflow secure?
We can learn a lot from the Python package breach involving Ultralytics. This breach highlighted the importance of making our PyPI publishing workflows for Python packages more secure.
In this breach, hackers exploited a GitHub Actions workflow to inject malicious code into a Python package. This package was then published to PyPI. The outcome: users who downloaded the package unknowingly allowed their machines to be hijacked for Bitcoin mining.
Hackers tricked a Python package into running bad code, using other people’s computers to mine Bitcoin without permission. Yikes!
While unsettling, there’s a silver lining: the PyPI security team had already addressed most of the issues that caused this breach.
Because the Ultralytics project was using Trusted Publishing and the PyPA’s publishing GitHub Action: PyPI staff, volunteers, and security researchers were able to dig into how maliciously injected software was able to make its way into the package.
This means that the important thing for us, as maintainers, is that we all should know how to lock down our publishing workflows.
Here, I’ll cover the lessons learned that you can apply TODAY to your Python packaging workflows!
The fall 2024 Ultralytics breach was a wake-up call for all maintainers: secure your workflows to protect your users and the Python ecosystem. The most important steps that you can take are actually the simplest:
Below are 3 things that you can do right now to secure your PyPI Python packaging workflow:
Secure GitHub–Human and GitHub–PyPI connections
🔒 If you have a GitHub Action that publishes to PyPI, make sure that the publish section of your action uses a controlled GitHub environment. Name that environment pypi and set environment permissions in GitHub that allow specific trusted maintainers to authorize the environment to run. I’ll show you how to do this below.
🤝 Create a Trusted Publisher link between your package’s (GitHub/GitLab) repository and PyPI. You can call this trusted connection within the locked-down GitHub environment (named pypi) that you created above.
🍒 Add zizmor to your build to check GitHub Actions for vulnerabilities. You can run zizmor on your workflow files locally, or you can set it up as a pre-commit hook which is probably a better bet.
Together, these three steps protect both sides of your PyPI publication process–the trigger on GitHub and the connection between GitHub and PyPI. 🚀🚀🚀
Don’t wait–start securing your Python publishing workflows today. 🔒
A call to (GitHub) actions …
The Ultralytics breach highlights the need for us all to follow and understand secure PyPI publishing practices and carefully monitor workflows. Below are actionable steps you can take to enhance security when publishing Python packages to PyPI using GitHub Actions.
1. Create a dedicated GitHub environment for publishing actions
First, make sure that your PyPI publish GitHub Action uses an isolated GitHub environment. Isolated environments ensure your publishing process remains secure even if other parts of your CI pipeline are compromised. This is because you can lock an environment down by ensuring that only specific users can authorize this environment to run.
If you look at the workflow example below, notice that we have an environment called pypi that is used for trusted publishing. The pypi environment creates a direct link between this action and PyPI Trusted Published (discussed below).
publish:name:>-Publish Python 🐍 distribution 📦 to PyPIif:github.repository_owner == 'pyopensci'needs:-buildruns-on:ubuntu-latestenvironment:name:pypiurl:https://pypi.org/p/pyosmeta
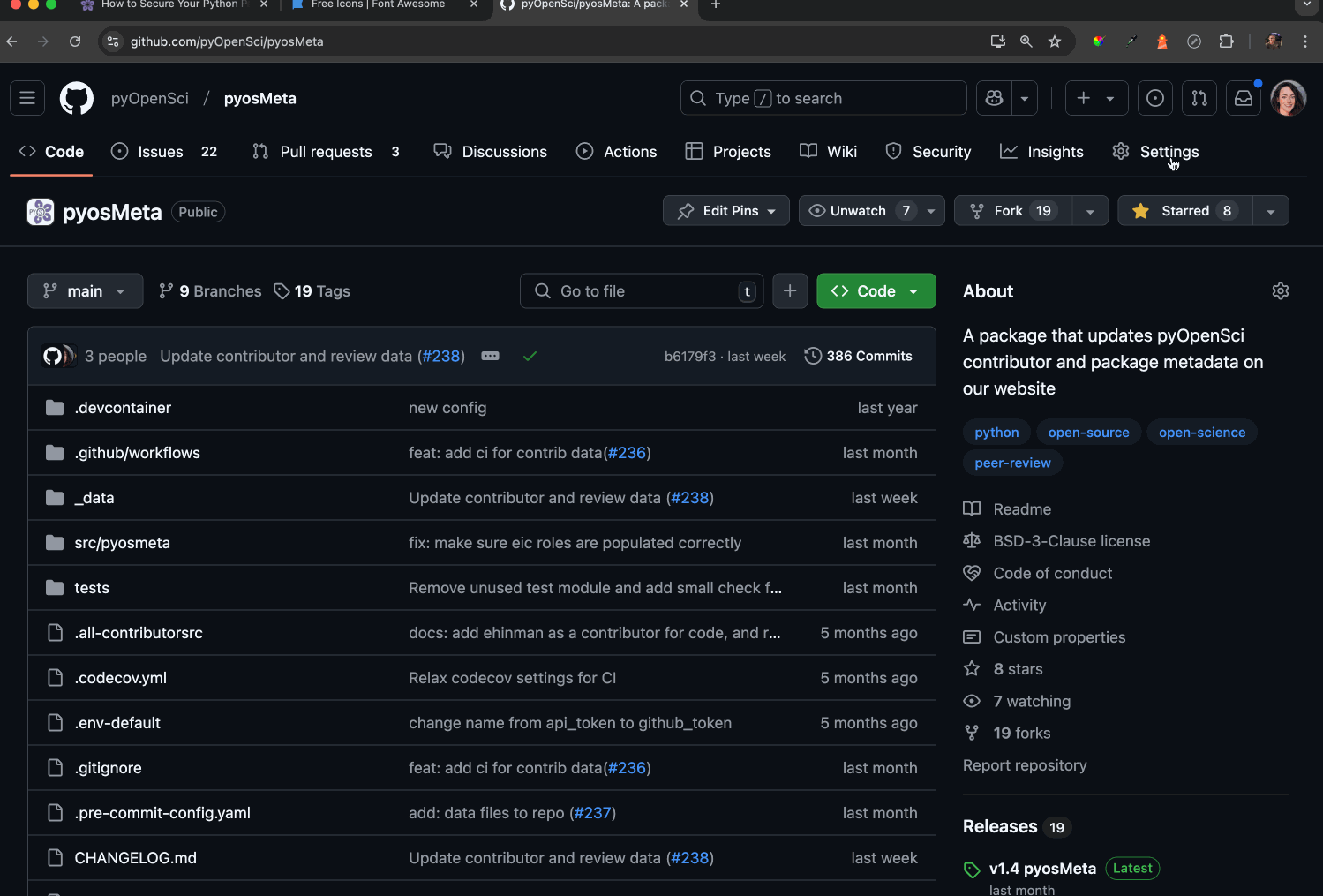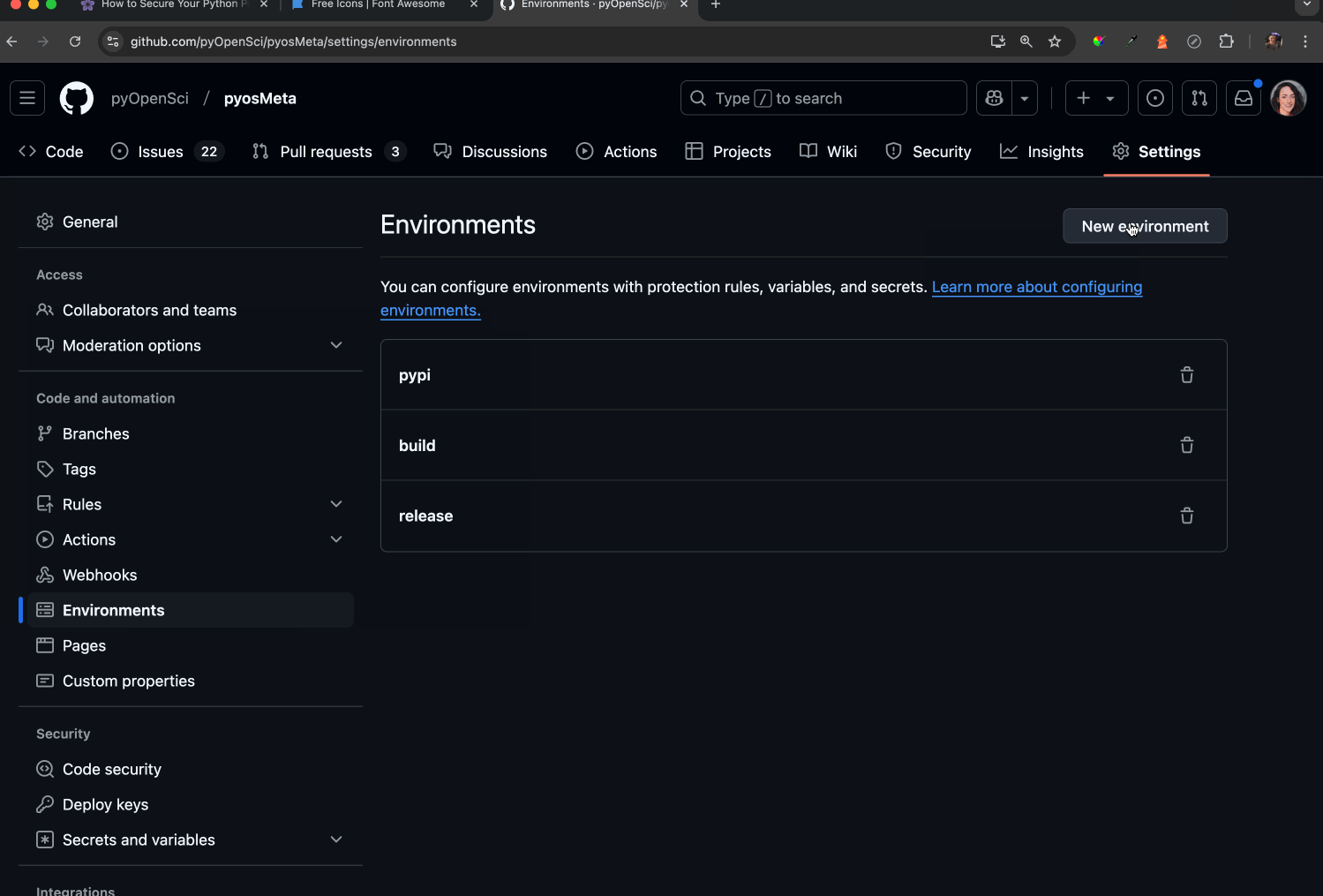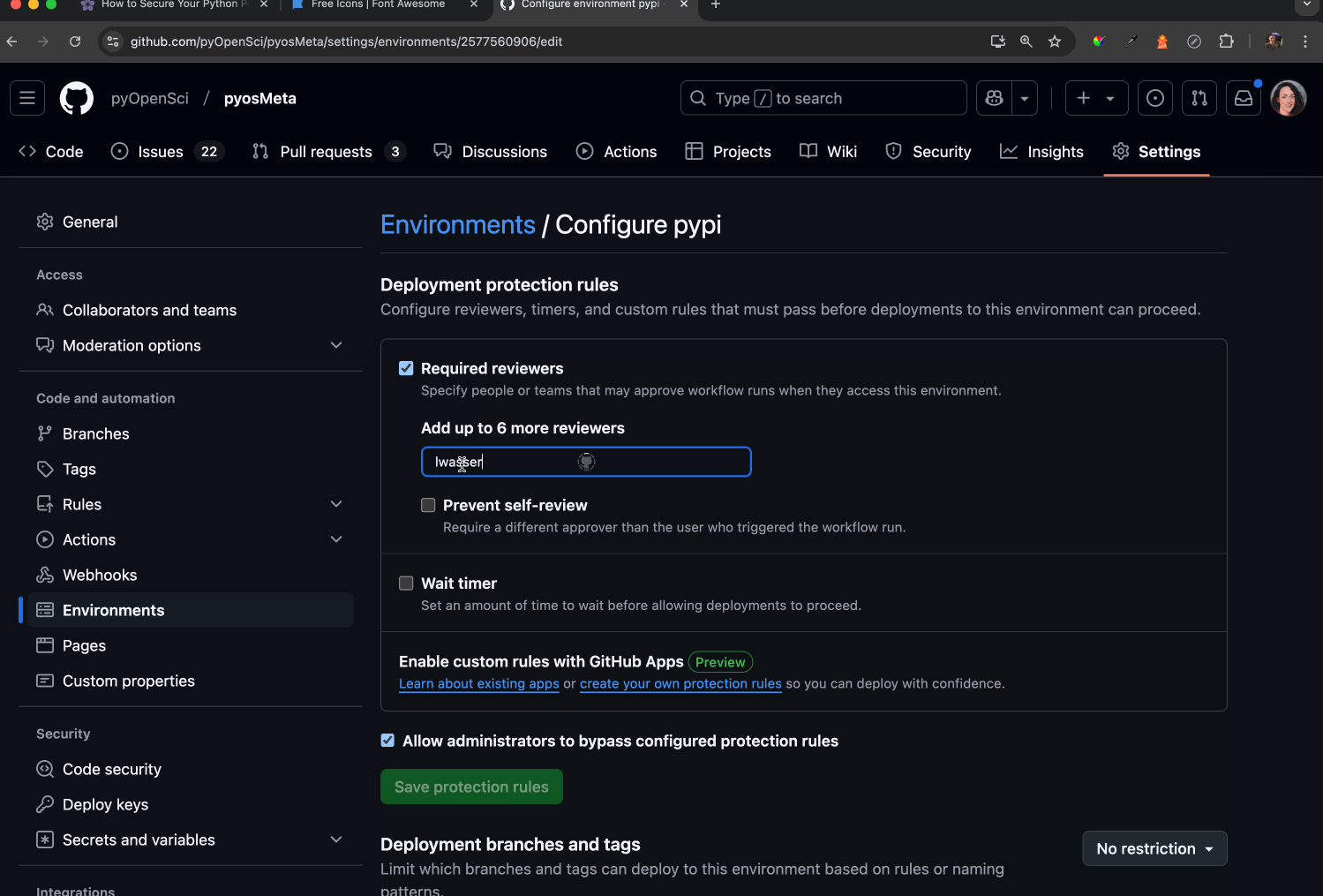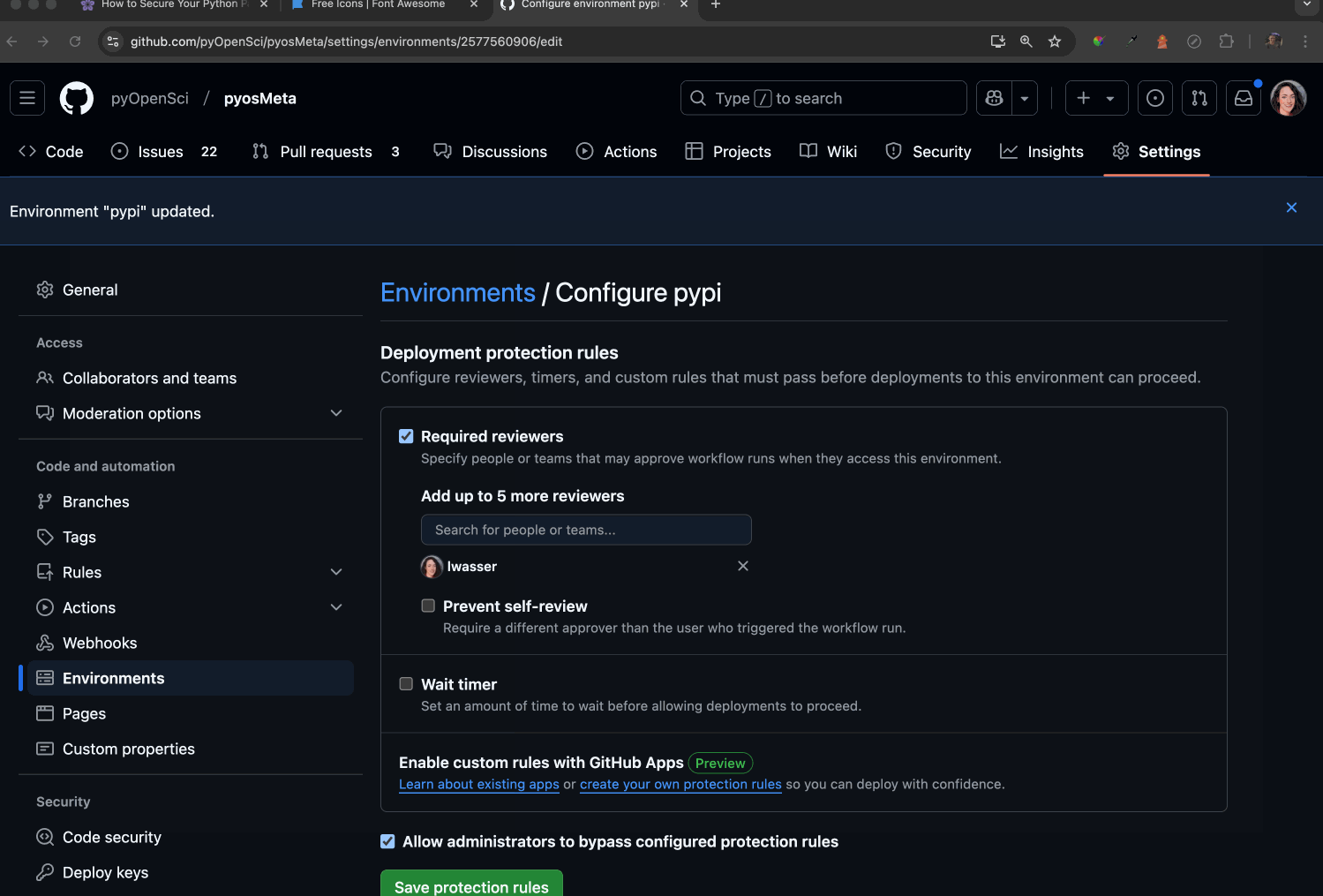
To lock down a GitHub environment:
First, go to the Settings in your repository where the workflow is run
Within settings, select environments from the left-hand sidebar
Add a new environment. Use pypi as your environment name; this is what PyPA (the Python Packaging Authority) recommends.
Ensure Required reviewers is enabled. This setting allows you to designate specific individuals who can approve and manually run the workflow on GitHub. Any reviewers you add must have the appropriate permissions to authorize the workflow by clicking a button. This adds a human verification step to the process.
Once the Required reviewers button is checked, add maintainers who you want to be able to enable the action to run.
Optionally, you can click prevent self-review, preventing someone from triggering a release or a build and then running it!
To create a new environment to use in a GitHub Action, 1) go to your repo's settings; 2) click environment; 3) add a new environment. In this screenshot, we already have a pypi environment created. Note that you can name your environment whatever you want, however, PyPI suggests that you use the name pypi for a Trusted Publisher workflow.
GitHub environment settings for “pypi,” displaying deployment protection rules with required reviewers configured for workflow approvals.
2. Use Trusted Publisher for PyPI
Now that you have a GitHub environment setup, you can set up Trusted Publisher in your PyPI account.
A Trusted Publisher setup creates a secure link between PyPI and your repository.
Trusted Publisher restricts publishing to a specific GitHub Actions workflows and environments defined in your repository.
Using a Trusted Publisher combined with a locked-down environment eliminates the need to store sensitive tokens as GitHub secrets. It also removes the need to refresh and update tokens periodically to avoid token leaks or theft issues.
Example of the PyPI Trusted Publisher form, used to securely link a GitHub repository with PyPI for publishing Python packages. Trusted Publisher reduces the risk of token theft and improves overall security.
If you only publish locally to PyPI using the command line, you must use a PyPI token. However, if you’re using GitHub Actions to automate your publishing process, setting up Trusted Publisher is a secure and easier-to-manage option.
Click on your profile to take you to Your projects.
Click on publishing on the left-hand side of the site. (it’s below account settings).
At the top of the page is a Manage Publishers section. At the bottom, you will see Add a new pending publisher
Fill out a form that looks like the one below in the add a new pending publisher section. Notice that you can select GitHub, GitLab, Google and ActiveState as platforms.
Notice that the form asks for your project name, owner, repo name, workflow’s file name, and environment (STRONGLY recommended).
Example of the PyPI Trusted Publisher form, used to securely link a GitHub repository with PyPI for publishing Python packages. Trusted Publisher reduces the risk of token theft and improves overall security.
For an example of a GitHub workflow that uses Trusted Publishing, check out our active pyOpenSci PyPI publishing GitHub workflow, which follows the Trusted Publisher approach.
Example of the PyPI Trusted Publisher setup in PyPI once you've created the Trusted PuUblisher link by filling the form out above.
Zizmor is a static analysis tool designed to help identify GitHub Action security issues. Zizmor scans your workflows and highlights common vulnerabilities, ensuring your continuous integration / continuous deployment pipelines remain secure and efficient.
Named as a playful nod to Dr. Zizmor’s famous “clear skin” ads, zizmor aims to give you “beautiful clean workflows.”
To use zizmor locally to check your workflows, first install it using pip or pipx:
pip install zizmor
Then, ask it to check a specific workflow file (or set of files).
Below, I ran it on our pyosMeta PyPI build. Among other things, it found a template injection risk in our build that we can easily fix by adding a sanitization step discussed below!
PyPI really is on top of things!
$zizmor .github/workflows/publish-pypi.yml
error[template-injection]: code injection via template expansion
-->path/here/pyosMeta/.github/workflows/publish-pypi.yml:97:7
github.ref_name may expand into attacker-controllable code
You can also set up zizmor as a pre-commit hook. pyOpenSci plans to do this in the future, but here is an example of it set up for core Python.
There are other things that we can learn too from the recent breach. Many of these will be identified if you set up zizmor. These are discussed below.
Sanitize branch names in your workflow
One of the critical issues in the Ultralytics breach involved a
malicious branch name containing a shell script
that was executed because github.ref was used without sanitization. This type
of attack, known as template injection, allows malicious content in branch
names to be treated as shell commands.
...is a classic GitHub Actions template injection: the expansion of `github.head_ref || github.ref` is injected directly into the shell’s context, with no quoting or interpolation..
Because the branch name wasn’t sanitized, it was treated as a shell command and executed with full permissions. Yikes!
In the example below, an unsanitized branch name could execute harmful commands:
jobs:example-job:runs-on:ubuntu-lateststeps:-name:Run a scriptrun:|echo "Running script for branch: $GITHUB_REF"
To prevent this, sanitize or clean branch names before using them. A small Bash step can
remove unsafe characters:
jobs:example-job:runs-on:ubuntu-lateststeps:-name:Sanitize branch namerun:|SAFE_BRANCH=$(echo $GITHUB_REF | sed 's/[^a-zA-Z0-9_\-\/]//g')echo "Sanitized branch name: $SAFE_BRANCH"echo "Running script for branch: $SAFE_BRANCH"
Lock down GitHub permissions & delete old PyPI tokens and GitHub secrets
In addition to securing your workflows, lock down your accounts and repositories. 2FA (2-factor authentication) is thankfully now required as a security measure for both GitHub and PyPI. However, be sure to store your recovery codes somewhere safe (like in a password manager!).
Also consider:
Revoking old tokens: If you’ve previously created PyPI API tokens and/or associated GitHub secrets, delete any unused or outdated ones.
Restrict repository access: Limit write GitHub repository access to a trusted subset of maintainers. Most contributors don’t need direct write access, which reduces security risks.
🚫 Avoid pull_request_target and consider release-based workflows
A trigger event in a GitHub Action is an event that sets off an action to run. For instance, you might have a trigger that runs a linter like Black or Ruff when a new pull request is opened.
The pull_request_target trigger event in GitHub Actions that Ultralytics used allows workflows to run with elevated permissions on the base branch, even when triggered by changes from a fork. Thus, your workflow becomes vulnerable when used as a trigger to push a release to PyPI.
Instead of a pull_request_target or a pull_request, consider adopting a release-based publishing workflow. This approach:
Triggers publication workflows only on new versioned releases. You can lock down which maintainers are allowed to create releases using GitHub permissions
Ensure workflows related to publishing are explicitly scoped to release events.
In the example GitHub Action .yaml file below, you see a release trigger defined. This tells the action to only trigger the workflow when you publish a release.
name:Publish to PyPIon:# By using release as a trigger, only GitHub users and actions with write access to make releases to our repo can trigger the push to PyPIrelease:types:[published]
Using a release-based workflow ensures that your publishing step is tightly controlled. A pull request will never accidentally trigger a publish build. This reduces your risk!
Don’t cache package dependencies in your publish step
Caching dependencies involves storing dependencies to be reused in future workflow runs. This approach saves time, as GitHub doesn’t need to redownload all dependencies each time the workflow runs.
However, caching dependencies can allow attackers to manipulate cached artifacts. If this happens, the workflow may pull in compromised versions from the cache during the next run.
Learn More
pyOpenSci follows best practices for PyPI publishing using our custom GitHub Actions workflow. Check out our tutorial on Python packaging here:
👉 pyOpenSci Packaging Tutorial
👉 Join our discourse here
Get involved with pyOpenSci
Check out our volunteer page if you are interested in getting involved.
Keep an eye on our events page for upcoming training events.
]]>Leah WasserBuilding Momentum for the Future: Reflections on Our First Open Science Festival Week2025-03-05T00:00:00+00:002025-03-05T00:00:00+00:00https://www.pyopensci.org/blog/pyOpenSci-first-open-science-festivalOur inaugural fall festival was a great success!
Three years ago, I envisioned an online event where our community could come together to celebrate open source and open science, share knowledge, and learn new skills. Last month, that vision became reality with pyOpenSci’s first-ever Fall Festival, held from October 28 to November 1. The event brought together 64 participants from over 15 countries—a global mix of researchers, developers, educators, and Python enthusiasts.
The week was packed with inspiring keynotes, hands-on workshops, and informal office hours, where participants connected and reflected on their learning.
What did you enjoy most about the fall festival:
Getting to know about pyOpenSci as an organization and resource. Also, [being provided with] practical, professional tools that I can use right away.
Acknowledging our amazing pyOpenSci team
Events like the Fall Festival don’t happen without an incredible team working behind the scenes to support every step of the process.
I want to extend our heartfelt gratitude to all the instructors, helpers, and keynote speakers who contributed their time and expertise to make this event truly special. Your dedication, energy, and enthusiasm ensured an engaging and impactful experience for everyone involved!
A special shout-out to Carol Willing, Jeremiah Paige, and Jonny Saunders, who supported multiple workshops and co-developed and reviewed many of the lessons now published online. We’re so lucky to have such an incredible community. 🫶
What made this event special
The vibe made this event special. The energy of participants who wanted to learn together was supported by the vibrant and knowledgeable pyOpenSci community. While many mentioned me directly, the vibe was more than just me. Our community came together to help scientists learn hard technical skills–together and without judgment.
I love the engagement…how people were attended to individually despite being in a group setting. I enjoyed that learning could happen in a personal and group setting.
We met learners where they were at!
The enthusiasm of Leah and her friends, Spatial chat and all new Python things I didn’t used before like Packaging, Great Tables, Quarto, Clean Code and Programming in [GitHub] CodeSpaces
Using the interactive platform SpatialChat rather than a traditional online platform like Zoom helped to create that vibe. More on that below.
Keynote talks
We kicked the event off on Monday, October 28, with a morning of KeyNote talks headlined by Eric Ma, Melissa Mendonça, and Rowan Cockett. The Monday talks aligned perfectly with the training events held Tuesday through Friday. The talks set the stage for a truly engaging week of learning together.
Eric Ma: The human side of clean code
Eric’s talk highlighted how simple practices like clear documentation, readable code, and user-friendly installation can amplify the impact of data science projects.
A standout moment? The “Roast Your Repo” exercise! Eric invited attendees to critique a repository from his thesis, showcasing the power of small improvements—like adding a fleshed-out README or modularizing code—to make research reusable and collaborative. It was a fun, hands-on way to explore how the human touch transforms code quality. And let’s be honest, we all likely have one of those code bases or repos from our early degrees! I sure do (and it’s not even on GitHub!).
Melissa Mendonça: From academia to open source
Melissa shared her journey from academia to open source software development, reflecting on the courage it takes to step into the unknown. She celebrated the scientific Python ecosystem, emphasizing how libraries like NumPy and SciPy enable countless domain-specific projects.
Melissa also highlighted the challenges of volunteer-driven communities, stressing the need for clear governance and transparent user engagement. Her focus on open science principles—transparency, reproducibility, and accessibility—was inspiring and reinforced the importance of collaborative, inclusive practices.
Rowan Cockett: Rethinking scientific publishing
Rowan invited us to imagine a future where scientific publications are as dynamic as the research they describe. He introduced Myst Markdown tools that blend code, data, and narrative and discussed his company, CurveNote, which aims to revolutionize scientific publishing.
His vision of collaborative, interactive, and automated publishing draws from open source principles and challenges the static nature of traditional papers. By rethinking how we share research, Rowan reminded us that we already have the tools to make science more immediately accessible and impactful.
Workshops and Quarto Live
We also invited George Stagg (Posit), developer of Quarto Live and James Balamuta to talk about how Quarto Live is empowering education. Quarto Live makes it easy for you to create interactive data science environments for learning in the browser.
Yes, it runs on GitHub pages - no servers needed.
Yes, students can write Python on their phones.
Both talks are below.
George Stagg
James Balamuta
Let the (open science & open source) learning begin!
The main “course” of the event was 4 days of active learning. Here, participants engaged in interactive workshops designed to build skills and confidence in writing, sharing, and publishing scientific code. Using SpatialChat, we created a dynamic and collaborative environment that fostered real-time learning and group discussions—something you just can’t replicate in traditional video call platforms like Zoom.
Our curriculum followed a clear narrative:
Write better code → Package it → Share it → Tell an interactive data story.
[I enjoyed….] Leah’s teaching style, the platform, and the tutorials. I felt very ease learning together with the pyOpenSci community.
Each day introduced new tools and practices to help participants transform their workflows and make their science more accessible, reusable, and impactful. Here’s how we approached it:
We introduced strategies to improve robustness, such as creating functions and using tests and checks to validate outputs.
Day 2: Create Your First Python Package
On Day 2, participants learned how to turn their code into reusable, installable Python packages. I’ve taught Python packaging with Hatch several times over the past year, and everyone consistently loves having an all-in-one tool! They also pick it up quickly, making the tool accessible and usable–a win-win! This was one person’s response to their favorite day:
…I thought Hatch was really useful and I liked the fact that it can do a couple of things as one tool.
Including a license to define how others can use and share your Python package.
Day 4: share your Python code (with everyone!)
On Day 4, we empowered participants to share their work more broadly. Many learners enjoyed this day which was cool for me because it was entirely new content I had never taught before but thought was so important to any scientist building software and writing code. Below, we asked them what day their favorite was. The theme of this response was common in the feedback:
[I enjoyed] making package installable via PyPI by using hatch (one often writes code, but never gets to this stage)
Day 5: Interactive data storytelling with Quarto & GreatTables
We wrapped up with an introduction to Quarto, a powerful tool for creating dynamic, interactive scientific narratives. Participants explored how to integrate code, data, and findings into a cohesive story—transforming static publications into living, engaging documents.
We also showcased Quarto Live, which lets users dynamically interact with code in the browser. For educators, this opens exciting opportunities to create lessons where students can learn directly in a live coding environment. How cool is that?
Fun fact: GreatTables has been accepted by pyOpenSci with the plan to be fast-tracked through the Journal of Open Source Software (JOSS) after the pyOpenSci review through our JOSS partnership.
Reflections on the 2024 pyOpenSci Fall Festival
The 2024 Fall Festival was an incredible learning experience for pyOpenSci! One of the standout successes was our last-minute switch to using Spatial Chat as our virtual platform. Participants loved how easy and intuitive it was to use, and it quickly became a seamless way to foster interaction and collaboration.
I liked the use of software like spatialchat, where you could break out into groups to work on things. This makes everything a lot more casual and fosters networking.
We were also thrilled to offer 16 scholarships for this event, making the festival accessible to diverse attendees.
We’re excited to continue improving our events to maximize engagement and accessibility for all community members. We look forward to building on this success for future festivals!
What’s next for pyOpenSci
Most of the resources used to teach are published on our pyOpenSci lessons website. We’re actively working on updates to incorporate additional content still housed in Google Docs, ensuring it’s accessible to all.
Looking ahead, we’re excited to run more events like this to support pyOpenSci’s broader mission of supporting the open source software scientists need to make their work open. We are planning to:
Develop a new set of lessons that support using GitHub collaboratively and empower contributors to make their first open source contributions.
Run online beginner-friendly sprints that further engage the community in making contributors to open source, no matter how big or small, we want to ease pain points!
Attend and run events at PyCon 2025 and SciPy 2025, holding events and connecting with you!
Check our blog and events page for upcoming events and opportunities to engage with the vibrant pyOpenSci community.
Support open science: Get involved with pyOpenSci
Volunteer to be an editor in our peer review process
Submit a scientific Python package to pyOpenSci for peer review
Donate to pyOpenSci to support scholarships for future training events and the development of new learning content.
check out our volunteer page for other ways to get involved.
You can also:
Keep an eye on our events page for upcoming training events.
]]>Leah Wasser2024: A Transformative Year for pyOpenSci2025-02-07T00:00:00+00:002025-02-07T00:00:00+00:00https://www.pyopensci.org/blog/pyopensci-2024-a-year-in-reviewIntroduction
In 2024, pyOpenSci’s vibrant community led efforts to make open source science more accessible, inclusive, and equitable for all. We empowered the broader community to create, contribute to, and discover better software through beginner-friendly training events, collaborative tutorials, and software peer review.
Looking back, I’m inspired and humbled by what we’ve achieved together:
As I reflect on an incredible year, I want to take a moment to celebrate these milestones and set the stage for an ambitious 2025. Here’s a look back at what we accomplished together in 2024 and where we’re heading next.
Co-creation of beginner-friendly content: Python packaging made easy(ier)
A defining strength of the pyOpenSci community is its commitment to co-creating accessible technical lessons for Pythonistas at all skill levels. These lessons, in turn, support our beginner-friendly tutorials and training events (more below). In 2024, this commitment shone through in creating our tutorial, “How to Create a Python Package”. This tutorial provides an opinionated way to create a Python package–a key step in making Python packaging more approachable and accessible for all.
Our packaging tutorial is the product of a vibrant collaboration between developers, scientists, and beginners. Packaging tool maintainers and packaging experts worked alongside those newer to packaging to co-develop, review, and refine content that is accurate, thorough, and welcoming to newcomers.
Collaborative learning in action: building together, learning together
Our co-development process brought contributors of all experience levels together to create a resource that:
Blend expertise: Developers and scientists shared insights, while beginners shaped the content with fresh perspectives.
Demystifies packaging: Clear, precise explanations, reviewed by experts and tested by newcomers, break down complex steps for new users.
Describes core concepts visually: Custom graphics and step-by-step guides make technical concepts easier for visual learners to grasp.
We’re building both knowledge and community by publishing these lessons as free, open-access resources. This collaborative effort exemplifies the unique power of pyOpenSci to bridge expertise, foster learning, and strengthen the open source ecosystem.
To further simplify the process of creating a new Python package, the community also came together to develop an easy-to-use Python packaging template. The template allows you to create a skeleton Python package that follows our beginner-friendly Python package tutorial with just a few commands.
Many learners used this template successfully during our Fall Festival (more below!) and we look forward to refining it further in the upcoming months.
Give it a test-drive and let us know what you think!
pyOpenSci’s training new training initiative: empowering our global community
In 2024, we launched the pyOpenSci training initiative to lower barriers and make scientific software education more accessible to all.
To further our commitment to equity, we awarded 25+ scholarships to support participation from a diverse group of students, researchers, and contributors.
Event Highlights: Fall Festival
Our first-ever Fall Festival featured inspiring keynote speakers like Rowan Cockett, who introduced participants to MyST Markdown, Melissa Mendoça who discussed her personal pathway into open source from academia, and Eric Ma, who overviewed the importance of reproducibility in science.
On the event’s last day, George Stagg, developer of Quarto Live, and James Balamuta kicked off the day with an overview of how Quarto Live makes interactive publishing of dynamic scientific outputs easier, connecting scientific workflows with shared outputs.
The dynamic spatial chat platform fostered real-time collaboration and made learning interactive, personalized, and fun!
I love the engagement…how people were attended to individually despite being in a group setting. I enjoyed that learning could happen in a personal and group setting.
Volunteer contributors who made it possible
The Fall Festival wouldn’t have been possible without the dedication of our incredible volunteers, who handled everything from workshop support to tech troubleshooting. Their efforts ensured a welcoming, smooth experience for participants.
Open education lessons from the Fall Festival
Participants didn’t just learn—they contributed! Thanks to the collaborative energy, the event produced several lessons that are now freely available to the community:
These lessons reinforce key technical skills and showcase the power of community-driven learning and co-creation.
Event highlight: Intro to Python packaging workshops
As a part of our training initiative, we also ran two beginner-friendly packaging workshops where dozens of participants successfully created their first Python packages by following our beginner-friendly packaging tutorials.
What did you enjoy most about the workshop?
The content and the crew! The team was so kind, patient, and approachable. I appreciate the amount of support and reassurance given during this tutorial. The content of the tutorial was also spot on. Everything we covered felt relevant and useful, and gave me the confidence to feel capable of creating my own packages.
The success of our training materials underscores the demand for inclusive, high-quality open science resources; they also demonstrate the power of community collaboration.
Expanding our software peer review program in 2024
The pyOpenSci software peer review program empowers scientists to build and improve the tools they rely on to process and analyze data. In 2024, we expanded our ecosystem of reviewed scientific Python packages to 39, thanks to the dedication of our editorial and review teams.
We also tried out a new editor in chief rotation system to avoid too much time burden on any specific editor. Below are our fearless EiC’s for 2024.
Our editorial team grew to 18 members, with a rotating Editor-in-Chief position, and was supported by 81 volunteer reviewers who contributed their time to ensure that every reviewed package in our ecosystem meets the highest standards for quality and usability.
Strengthening ecosystems through domain-specific affiliation: Astropy:
Our domain-specific community partnership program accepted three packages for Astropy affiliation. Our partnership with Astropy and JOSS demonstrates how communities with some overlapping goals can truly work together effectively.
Navigating ethical challenges in generative AI
In 2024, we began to address the emerging challenge of reviewing packages that rely on proprietary generative AI models. We discussed important ethical questions about transparency vs. innovation in scientific software. Should we review packages that depend upon proprietary (closed box) models that are rapidly evolving?
More work is needed, and we are committed to handling these complexities as we always do–collaboratively and with great care.
A thriving, diverse contributor community: how contributions to pyOpenSci have skyrocketed
In 2024, pyOpenSci welcomed 278 contributors from diverse backgrounds, many making their first-ever open source contributions. By prioritizing mentorship, accessibility, and community-led learning, we helped first-time contributors gain the confidence and skills to shape the future of open source science.
This was also the first year where volunteer contributions outnumbered staff contributions—a testament to the power of community.
Wow!
Plot that shows an increase in contributions to pyOpenSci open education content.
Empowering first-time contributors
A key driver of contributor and community growth was our beginner-friendly sprints. Sprint events exemplified the power of community support combined with mentorship & just a bit of training (mostly around git and GitHub). These sprints welcomed over 50 participants and resulted in 86 issues and pull requests—many from first-time contributors.
PyCon US, SciPy, and PyCascades Sprints: Hosted across three major conferences, these events focused on hands-on mentorship, guiding participants through impactful contributions.
Amazing! Leah was so helpful as it was my first time doing anything like that. I had used GitHub for personal projects but never with other people so she was so good at teaching.
Our sprints strengthened our contributor community and sparked new initiatives, like translating our packaging guide into Spanish and Japanese.
Funding and sustainability
In 2024, we reached an important milestone in pyOpenSci’s journey. Our initial funding from the Sloan Foundation, which gave us our start as a fledgling project, ended in December. The Sloan Open Source Program’s generous support took us a long way—it helped me grow pyOpenSci from a part-time passion project into a thriving community dedicated to lowering barriers to open source scientific software.
We are deeply grateful for Sloan’s belief in our vision and commitment to open science. Last fall, we also received support from the Chan Zuckerberg Initiative (CZI), which will empower us as we move forward. This combined funding has enabled us to launch our training initiative, expand our peer review program, and co-develop beginner-friendly lessons and tutorials.
Building the future: new initiatives and funding efforts
As we look to the future, our current focus includes:
Exploring funding models for pyOpenSci
Growing our peer review partners and program
Connecting with University OSPOS (Open Source Program Offices)
A focus on empowering the community to contribute to open source
Educational Videos that support our online content
Strong together: Why inclusion in open science matters now more than ever
At a time when access, equity, and sustainability in open science face challenges, we believe in building a space where everyone—regardless of background—can contribute, learn, and thrive. Diversity strengthens open source, and we are committed to ensuring that our community remains welcoming, supportive, and accessible.
Sustaining our impact
As we head into 2025, sustainability and our commitment to diversity, equity, inclusion and accessibility remains a top priority. We’re committed to growing pyOpenSci in ways that support our contributors, empower learners, and strengthen open source science. We’re actively seeking new partnerships, welcoming new contributors and funding opportunities to ensure our work continues to thrive.
To our funders, contributors, and community members—thank you. Your support makes our work possible and helps us build a future where scientific software is open, accessible, and collaborative.
As we reflect on where we’ve been and where we’re going, it’s important to acknowledge the teams that continue to guide our vision and growth.
Our leadership teams—including the Executive Council, Advisory Council and
Peer Review Editorial Board have been instrumental in carving the path forward for pyOpenSci.
We look forward to building the future of open science, one contribution at a time—and we invite you to join us on this journey.
Get involved with pyOpenSci
If you’d like to get involved with pyOpenSci, check out our volunteer page.
You can also:
Keep an eye on our events page for upcoming training events.
]]>Leah WasserQuadratiK: Collection of Methods Constructed using Kernel-Based Quadratic Distances2025-01-17T00:00:00+00:002025-01-17T00:00:00+00:00https://www.pyopensci.org/blog/quadratikIntroduction
QuadratiK provides a suite of methods based on kernel-based quadratic distances, and hence the name!
QuadratiK contains several goodness of Fit (GoF) tests such as normality tests and two and k-sample tests. It also includes tests for uniformity on the d-dimensional sphere, a clustering algorithm using Poisson kernel densities, and algorithms for generating random samples from PKBD. QuadratiK offers graphical functions that enhance user experience by facilitating the validation, visualization, and interpretation of clustering results. Furthermore, it provides methods for meaningful analyses and reproducible inference across diverse fields. A dashboard application with a user-friendly interface is also a part of QuadratiK to enhance accessibility for practitioners beyond the domain of statistical sciences.
This package is joint work with Dr. Marianthi Markatou, SUNY Distinguished Professor, University at Buffalo and Dr. Giovanni Saraceno, Assistant Professor, University of Padova.
Goodness-of-Fit (GoF) Tests
Goodness-of-Fit (GoF) tests are classical tools for assessing the compatibility of data with a given probability model. GoF tests typically compute a distance-like metric between the null distribution and observations, rejecting the null hypothesis if the distance exceeds a critical value.
The methods for normality, two-sample, and k-sample test use a bandwidth parameter h. We have also provided an algorithm for determining the optimal value of h based on the mid-power analysis (please see Markatou and Saraceno (2024)). You can find more details on algorithm in our manual.
In this section, the various GoF tests are shown with corresponding examples.
Normality Test
Normality tests are used to determine if the sample data is well-modeled by a normal distribution. In our case, this is done by measuring the distance between the sample data and the target distribution, where the target distribution in this case is the d-dimensional normal distribution.
In our case, this is done by measuring the distance between the empirical cumulative distribution function of the sample data and the target distribution, where the target distribution in our case is the d-dimensional normal distribution.
iimportnumpyasnpnp.random.seed(0)fromQuadratiK.kernel_testimportKernelTest# data generation
data_norm=np.random.multivariate_normal(mean=np.zeros(4),cov=np.eye(4),size=500)# performing the normality test
normality_test=KernelTest(h=0.4,num_iter=150,method="subsampling",random_state=42).test(data_norm)# printing the summary for normality test
print(normality_test.summary(print_fmt="grid"))
The results of this test is shown below.
The test rightly fails to reject the null hypothesis, as the samples have been generated from a standard normal distribution.
Two-Sample Test
The two-sample GoF test is used to determine whether two separate samples are likely drawn from the same population distribution.
To illustrate the two sample test, we generate n = 200 random samples from a multivariate standard normal distribution and a skewed normal distribution with value of skewness parameter lambda = 0.1.
importnumpyasnpnp.random.seed(0)fromscipy.statsimportskewnormfromQuadratiK.kernel_testimportKernelTest# data generation
X_2=np.random.multivariate_normal(mean=np.zeros(4),cov=np.eye(4),size=200)Y_2=skewnorm.rvs(size=(200,4),loc=np.zeros(4),scale=np.ones(4),a=np.repeat(0.1,4),random_state=20,)# performing the two sample test
two_sample_test=KernelTest(h=2,num_iter=150,random_state=42).test(X_2,Y_2)# printing the summary for the two sample test
print(two_sample_test.summary(print_fmt="grid"))
The results of the test is shown below.
The test rejects the null hypothesis, as the samples have been generated from two different distributions.
K-Sample Test
Similar to the two-sample test, the k-sample test examines whether k groups of samples are obtained from the same distribution.
For illustrating the k-sample test, we use the glass identification dataset from the UCI ML repository. We use the first three classes of glass types to illustrate the working of the k-sample test.
# Importing required libraries
fromucimlrepoimportfetch_ucirepoimportnumpyasnpfromQuadratiK.kernel_testimportKernelTest# Fetching the dataset
glass_identification=fetch_ucirepo(id=42)# Selecting the data for specified types of glass
filtered_data=glass_identification.data.original.query("Type_of_glass in [1, 2, 3]")X=filtered_data.drop(columns=['Type_of_glass'])y=filtered_data['Type_of_glass'].to_numpy()# Setting random seed
np.random.seed(0)# Performing the Kernel Two-Sample Test
k_sample_test=KernelTest(h=2,num_iter=150,random_state=42).test(X,y)# Printing the test summary
print(k_sample_test.summary(print_fmt="grid"))
The results of the test is shown below.
The null hypothesis is rejected for the k-sample test indicates that there is significant evidence to conclude that at least one of the distributions among the three glass types is different. In other words, the samples from the three classes of glass do not all come from the same underlying population distribution. This suggests that there are meaningful differences in the characteristics or features of the glass types being compared.
Uniformity Test on the Sphere
In this we test the null hypothesis of uniformity on the sphere. We illustrate this test using an example.
The data for this example is generated from a multivariate standard normal distribution, and is further divided by the L2 norm of generated vectors. This processed data is uniformly distributed on the surface of the unit sphere.
importnumpyasnpnp.random.seed(0)fromQuadratiK.poisson_kernel_testimportPoissonKernelTest# data generation
z=np.random.normal(size=(500,3))data_unif=z/np.sqrt(np.sum(z**2,axis=1,keepdims=True))# performing the uniformity test
unif_test=PoissonKernelTest(rho=0.5,random_state=42).test(data_unif)# printing the summary for uniformity test
print(unif_test.summary(print_fmt="grid"))
The results of the test is shown below.
Clustering
QuadratiK implements the Poisson kernel-based clustering algorithm on the sphere proposed by Golzy and Markatou (2020). We will demonstrate the spherical clustering capabilities of QuadratiK through an image segmentation task.
The image we will be using is shown below, and the task is to identify the various regions (eg. entity or other features on interest in an image).
Particularly, in this image a potential image segmentation task is to identify the various entities i.e. the cat and the dog in the image. Let’s apply the clustering algorithm and see what does it return to us.
importmatplotlib.pyplotaspltfromPILimportImageimportnumpyasnp# Load and resize the image
image=Image.open("dog-cat.png")new_size=(50,50)# Width, Height
image=image.resize(new_size)# Convert the image to a NumPy array
image_array_resized=np.array(image,dtype=float).reshape((-1,3))image_array_resized=image_array_resized+10**-6# Avoid division by zero
# Apply Poisson Kernel Based Clustering
fromQuadratiK.spherical_clusteringimportPKBCk_values=range(2,11)pkbc=PKBC(num_clust=k_values,random_state=0).fit(image_array_resized)segmented_images=[]plt.figure(figsize=(16,8))num_k_values=len(k_values)num_cols=6num_rows=(num_k_values+num_cols-1)//num_colsfori,kinenumerate(k_values,start=1):labels=pkbc.labels_[k]labels_reshaped=labels.reshape(new_size[1],new_size[0])np.random.seed(42)unique_labels=np.unique(labels)colors=np.random.randint(0,255,size=(len(unique_labels),3))segmented_image=np.zeros((new_size[1],new_size[0],3),dtype=np.uint8)forlabelinunique_labels:segmented_image[labels_reshaped==label]=colors[label]segmented_images.append(segmented_image)# Plot segmented image
plt.subplot(num_rows,num_cols,i)plt.imshow(segmented_image)plt.axis('off')plt.title(f"Segmented (k={k})")plt.tight_layout()plt.show()
The image is segmented into k clusters with k ranging from 2 to 8. Below, we display the regions identified for each value of k.
Starting from k = 5, the segmented images reveal only minor changes in the identified segments upon closer examination. Let us see if we can validate our observation using the elbow plots.
The elbow plots show a clear elbow at k = 5, which aligns with our observation that all regions of the image are effectively identified at this value of k.
The clustering algorithm proposed in Golzy and Markatou has been used in other works such as Golzy et al. (2023), Strelnikoff at al. (2020), and Strelnikoff et al. (2024).
Sampling from PKBD
In this example, we generate observations from the Poisson kernel-based distribution on the sphere. QuadratiK in Python implements two algorithms to generate random samples, the acceptance-rejection algorithm using the Mises-Fisher and angular central Gaussian distributions. In the example, we consider mean direction $\mu = (1,1,1)$ and dimension d = 3 with concentration parameter $\rho = 0.9$. We sample n = 500 observations for the available methods.
# Import the PKBD class from the spherical_clustering module in the QuadratiK package
fromQuadratiK.spherical_clusteringimportPKBD# Instantiate the PKBD class
pkbd=PKBD()# Generate 500 samples from PKBD using rejvmf
samples_rejvmf=pkbd.rpkb(n=500,mu=[1,1,1],rho=0.9,method="rejvmf",random_state=42)# Generate 500 samples PKBD using rejacg
samples_rejacg=pkbd.rpkb(n=500,mu=[1,1,1],rho=0.9,method="rejacg",random_state=42)
The generated samples can also be visualized on the unit sphere.
importmatplotlib.pyplotaspltimportnumpyasnp# Plot samples on unit sphere
phi,theta=np.mgrid[0:np.pi:100j,0:2*np.pi:100j]x=np.sin(phi)*np.cos(theta)y=np.sin(phi)*np.sin(theta)z=np.cos(phi)fig=plt.figure(figsize=(5,5))ax=fig.add_subplot(111,projection="3d")ax.view_init(azim=50,elev=30)ax.plot_surface(x,y,z,color="white",alpha=0.8,linewidth=0)ax.scatter(samples_rejvmf[:,0],samples_rejvmf[:,1],samples_rejvmf[:,2],color="b",s=25,marker="*",label="rejvmf",)ax.scatter(samples_rejacg[:,0],samples_rejacg[:,1],samples_rejacg[:,2],color="red",s=25,marker="o",label="rejacg",)ax.set_xlim([-1,1])ax.set_ylim([-1,1])ax.set_zlim([-1,1])ax.set_aspect("equal")ax.tick_params(axis="both",labelsize=8)plt.legend(loc="upper right",fontsize=14)plt.tight_layout()
More details on Poisson Kernel-Based Distributions can be found in the package documentation here.
Dashboard
QuadratiK also provides a graphical user interface (GUI) that enables users to interact with its methods in a non-programmatic and user-friendly manner.
fromQuadratiK.uiimportUIUI().run()
Concluding Remarks
QuadratiK provides methods to researchers and practitioners to delve deeper into their data, draw robust inference, and conduct potentially impactful analyses and inference across a wide array of disciplines. The QuadratiK package is also available in R and is hosted on CRAN. You can learn more about QuadratiK in our arXiv preprint. Additional theoretical papers of interest are listed in the reference section.
Please feel free to reach me at raktimmu at buffalo.edu.
Thank you! Happy coding to you — may your bugs be few, and your data ever insightful! 🚀😊
References
Saraceno G., Markatou M., Mukhopadhyay R., Golzy M. (2024). Goodness-of-Fit and Clustering of Spherical Data: the QuadratiK package in R and Python. arXiv preprint arXiv:2402.02290.
Ding Y., Markatou M., Saraceno G. (2023). “Poisson Kernel-Based Tests for Uniformity on the d-Dimensional Sphere.” Statistica Sinica. DOI: 10.5705/ss.202022.0347.
Golzy M. & Markatou M. (2020) Poisson Kernel-Based Clustering on the Sphere: Convergence Properties, Identifiability, and a Method of Sampling, Journal of Computational and Graphical Statistics, 29:4, 758-770, DOI: 10.1080/10618600.2020.1740713.
Sablica, L., Hornik, K., & Leydold, J. (2023). Efficient sampling from the PKBD distribution. Electronic Journal of Statistics, 17(2), 2180-2209.
Markatou, M., & Saraceno, G. (2024). A unified framework for multivariate two-sample and k-sample kernel-based quadratic distance goodness-of-fit tests. DOI: 10.48550/arXiv.2407.16374v1
Golzy, M., Rosen, G. H., Kruse, R. L., Hooshmand, K., Mehr, D. R., & Murray, K. S. (2023). Holistic assessment of quality of life predicts survival in older patients with bladder cancer. Urology, 174, 141-149.
Strelnikoff, S., Jammalamadaka, A., & Warmsley, D. (2020, December). Causal maps for multi-document summarization. In 2020 IEEE International Conference on Big Data (Big Data) (pp. 4437-4445). IEEE.
Strelnikoff, S., Jammalamadaka, A., & Warmsley, D. M. (2024). U.S. Patent No. 11,907,307. Washington, DC: U.S. Patent and Trademark Office.
]]>Raktim MukhopadhyaypyOpenSci is hiring a Communications Lead2024-12-13T00:00:00+00:002024-12-13T00:00:00+00:00https://www.pyopensci.org/blog/pyOpenSci-job-communicationsJob: writer & social media specialist
Last Updated: 2024-12-19
About the role
pyOpenSci seeks a talented Writer and Social Media Specialist to enhance our communications and engagement with the scientific Python community. This position involves crafting engaging content highlighting our online learning content, tutorials, events, and package ecosystem for our social media channels, newsletters, and blog to keep our community informed and inspired. It also involved reviewing and editing educational content. This is an excellent opportunity for someone passionate about open science and skilled in clear, impactful communication. The position requires 10-15 hours per week at a rate of 25-40$/hour based on experience, with the flexibility of remote, part-time work. There is some flexibility in this position week-to-week based on pyOpenSci’s deadlines. This is a non-regular, part-time, remote, non-exempt position. This position will report
to the pyOpenSci Executive Director. Applicants must be eligible for employment in the United States.
About pyOpenSci
pyOpenSci is a vibrant and diverse scientific open source community that develops processes and guidelines for creating and maintaining scientific Python packages and develops educational content around creating Python packages, sharing code, and engaging in open science practices. Our mission is to help make science more open and collaborative while also increasing the participation of groups that have been traditionally underrepresented in the open source community.
pyOpenSci runs an open peer review process for scientific Python software. Through this program, we reinforce community-defined packaging guidelines while improving usability, documentation, and package quality. Further, we are curating a database of vetted scientific Python tools that are actively maintained.
A core part of our mission is to increase the participation of historically underrepresented groups in open science and open source. We achieve this by providing mentorship, translating resources, offering training scholarships, and partnering with global organizations.
pyOpenSci is a fiscally sponsored project of Community Initiatives.
Key responsibilities
Social Media Management: Create and schedule posts on platforms including Mastodon, LinkedIn, BlueSky, and YouTube. Ensure our content is engaging, consistent, and aligns with pyOpenSci’s mission.
LinkedIn is currently our most active platform. As such, you will spend time writing our LinkedIn newsletters and developing graphic and text content for posts that keep the community up-to-date and engaged with our efforts.
pyOpenSci currently uses Buffer to manage scheduled posts and associated analytics.
Content Creation: Write and edit newsletters, blog posts, and other materials to update our community on pyOpenSci’s programs, new resources, and events.
Create supporting graphics to enhance engagement.
Contribute to and review online lessons being developed by pyOpenSci
Community Engagement: Interact with our online community to foster engagement, respond to questions, and keep conversations aligned with our goals.
Content Planning: Work with the pyOpenSci team to develop a content calendar that supports key events, initiatives, and outreach goals.
pyOpenSci also has plans to launch a YouTube channel. Video editing skills are not required for this position but are a bonus.
What we’re looking for
Communication Skills: Excellent written communication skills with experience creating strategic content for social media, blogs, and newsletters.
Community-Oriented: Passion for engaging with the scientific community and supporting our open science mission.
Attention to Detail: Strong proofreading skills and a knack for creating polished, professional, engaging content.
Organized and Reliable: Ability to work independently, manage time effectively, and meet deadlines in a remote environment.
Visual Content Creation Skills: Proficiency in creating visually appealing social media graphics with an eye for design and aesthetics, ensuring content is engaging and on-brand.
About You
Broadly familiar with open science and open source principles and excited about developing content that promotes these principles.
Experienced in science communication, writing, or a related field.
Fluent in written and spoken English.
Preferred but not required qualifications
Experience using Python and Git/GitHub.
Familiarity with video content creation or editing.
What you can expect
In this role, you’ll work closely with our executive director and engage with the pyOpenSci community to amplify our message and increase our visibility. You’ll be able to contribute creatively to our communications and make a tangible impact on the open science movement.
Equal employment opportunity
Community Initiatives is an equal opportunity employer and considers applicants for employment regardless of age, race, color, religion, creed, sex, sexual orientation, gender identity or expression, national origin, marital status, disability, or protected veteran status.
How to apply
We encourage applications from candidates of all backgrounds, especially those traditionally underrepresented in open science and open source communities.
To apply, please email admin@pyopensci.org with the following:
A current resume.
A cover letter that discusses your experience developing social content. In that cover letter, please include at least one link, image, or example of each of the following:
Social posts that you have created (ideally with graphics you have created),
A blog post that you have written that you are proud of
Optional: If you have created video content before, please include an example.
Please submit example materials as links or attachments as you see fit.
Applications will be reviewed on a rolling basis.
]]>Leah WasserThe Human Dimension to Clean, Distributable, and Documented Data Science Code2024-10-28T00:00:00+00:002024-10-28T00:00:00+00:00https://www.pyopensci.org/blog/human-dimension-data-scienceThis post was originally posted on Eric’s blog in support of the 2024 pyOpenSci Open Science Fall Festival.
Introduction
Since 2016 (8 years now!),
I’ve been advocating for data scientists
to apply basic software development practices in their work.
This means making sure that one’s work is well-documented – and thus easily understandable,
working in a way that is portable across machines – and thus easily accessible,
making sure that one’s code is modular – and thus easy to reuse,
and ensuring that one’s code is well-tested – and thus reliable. (Table 1)
In this post,
we’ll dive deeper into why it is crucial for making your work impactful
to consider the psychology of people
who read, install, and use your work.
We’ll explore the “why” behind the “what”
that will be covered in the upcoming pyOpenSci training course.
This training course will be teaching you a lot of valuable skills - the “what to do” -
and I’d like to help reinforce the “why” behind all of these.
By understanding the reasoning and motivation behind these practices,
you’ll be better equipped to apply them effectively
and adapt them to your specific needs in data science projects.
Practice
Benefit
Well-documented
Easily understandable
Portable across machines
Easily accessible
Modular code
Easy to reuse
Well-tested code
Reliable
Table 1: Key practices and their benefits in data science code development.
Key concept 1: readability and cognitive load
When we write code,
it’s easy to forget that we’re not just communicating with machines,
but with other humans as well - including our future selves.
This principle is deeply ingrained in Python’s philosophy,
as expressed in “The Zen of Python” which states,
“Readability counts.”
Python’s emphasis on readability over performance
underscores the importance of human-friendly code.
Readability is crucial because it directly impacts the cognitive load
placed on anyone trying to understand or use your code.
The importance of readability
Readable code offers several significant benefits.
First and foremost, it enables faster comprehension.
When code is clean and well-structured,
readers can quickly grasp its purpose and functionality,
allowing them to understand the logic and flow more efficiently.
This leads to the second advantage: easier maintenance.
Code that is easy to read is also easier to debug, update, and extend,
saving valuable time and resources in the long run.
Furthermore, readable code greatly improves collaboration!
When team members can easily understand each other’s code,
it fosters better teamwork and enables them to build upon each other’s work more effectively.
This synergy can lead to more innovative solutions and faster project completion.
Lastly, clear and readable code reduces the likelihood of errors.
When code is easy to interpret,
there’s less chance of misunderstanding its intent or functionality.
This clarity minimizes the risk of introducing bugs during modifications
or when integrating with other parts of the system,
ultimately leading to more robust and reliable software.
A cautionary tale from my graduate school days
During my graduate studies,
I developed a complex data analysis project
for identifying putative reassortant influenza viruses
from the Influenza Research Database (IRD).
While the algorithm was scientifically sound and potentially valuable,
its implementation left much to be desired
from a software engineering perspective.
The project consisted of more than 10 separate Python scripts
that had to be executed in a specific order.
There was little to no documentation,
and the code itself was not written with readability or maintainability in mind.
You can find the original code repository here
to see an example of what not to do.
The project had several significant drawbacks:
Lack of modularity: The scripts were tightly coupled, making it difficult to reuse or modify individual components.
Poor documentation: Without clear documentation, understanding the purpose and workflow of each script was challenging.
Difficult deployment: The complex execution order and tight coupling to a GridEngine HPC cluster made it nearly impossible for others to deploy or use the tool effectively.
The consequences of this poor code quality
became apparent when the IRD team
expressed interest in incorporating my algorithm into their database.
I remember being engaged with them in discussion,
and was excited to see my work potentially being used
by researchers around the world.
However, the barrier to deployment was immense
due to the scrappy implementation and lack of documentation.
While I never knew what the real reasons were behind-the-scenes,
I can only imagine that the lack of a well-documented,
modular, and easily deployable solution
was a major barrier to the adoption of my work.
This experience taught me a valuable lesson
about the importance of writing clean, well-documented, and easily deployable code,
even in academic settings.
Had I invested more time in proper software development practices,
my work could have had a much broader impact
and been more easily adopted by the scientific community.
The impact of readability
By prioritizing readability,
we can significantly enhance the overall quality and impact of our data science projects.
Readable code:
Reduces the cognitive load on users, making it easier for them to understand and use your code.
Encourages collaboration and knowledge sharing within the data science community.
Improves the maintainability and longevity of your codebase.
Enhances the overall credibility and professionalism of your work.
Remember, the goal is to create tools and analyses
that others can easily access, understand, and build upon.
By embracing the human dimension of our code,
we not only improve our individual projects
but also contribute to the growth and accessibility
of the entire field of data science.
Key concept 2: User-friendly installation and setup
The ease of installation and setup
can make or break the adoption of your data science package.
Even the most brilliant code is useless
if users can’t get it running on their systems.
Let’s explore the psychological barriers users face
and how to overcome them.
The psychology of installation friction
When users encounter complex installation processes,
they often face several psychological barriers.
Barrier 1 - Complexity:
First, the sheer complexity can be overwhelming,
causing users to abandon the installation before they even begin.
This initial hurdle can be particularly daunting
for those who are less technically inclined
or new to the field.
Barrier 2 - Frustration:
Secondly,
users may experience frustration when installations fail
or when they encounter unclear error messages.
These setbacks can be discouraging,
potentially leading users to give up on further attempts to install and use the software.
I remember the early days of installing SciPy!
Nowadays, it’s so easy:
pip install scipy or conda install scipy and you’ve got it installed.
But back then, I was wrangling C compilers and linker flags at the terminal…
as a 3 month old programmer!
Anyways, the negative emotions associated with these experiences
can create a lasting impression,
deterring users from trying again in the future.
Barrier 3 - Time Pressure:
Many users, particularly those in professional settings,
have limited time to experiment with new tools.
If the installation process is time-consuming or requires multiple attempts,
your potential users may decide that the potential benefits of the tool
are not worth the time investment required to get it up and running.
Your impact, as a result, is diminished –
especially because your users missed the opportunity
to leverage what you’ve built!
Barrier 4 - Imposter Syndrome:
Difficulties in the setup process
can trigger feelings of imposter syndrome.
When users struggle to install or configure a tool
that they believe should be straightforward,
they may begin to question their own competence.
This self-doubt can be a powerful deterrent to adoption,
as users may avoid tools
that make them feel inadequate or out of their depth.
Two perspectives on setup: User vs. Developer
When we talk about “getting set up” with a data science package or project,
it’s important to recognize that this can mean two distinct things,
depending on the user’s intentions:
Installing a tool for use:
This is the perspective of an end-user who wants to leverage your package as a tool in their own work.
They’re primarily concerned with getting the package installed and running quickly,
without needing to understand or modify the underlying code.
Installing to contribute:
This is the perspective of a developer or contributor
who wants to explore, modify, or contribute to your project’s code.
They need to set up a full development environment,
which often involves more steps and a deeper understanding of the project structure.
Each of these scenarios presents its own set of challenges and psychological barriers:
For tool users, the focus is on simplicity and speed.
They want a straightforward installation process,
ideally with a single command like pip install your-package.
Complex dependencies or platform-specific instructions can be major deterrents.
For developers, the process is inherently more involved.
They need to clone the repository,
set up a virtual environment,
install development dependencies,
and possibly configure additional tools like linters or test runners.
While they may be more technically inclined,
a clear and well-documented setup process is still crucial to encourage contributions.
By recognizing and addressing both of these perspectives in your documentation and setup process,
you can create a more inclusive and user-friendly experience for all potential users of your project,
whether they’re simply using it as a tool or diving deep into the code.
The impact of user-friendly setup
By prioritizing a smooth installation and setup process:
You lower the barrier to entry for potential users.
You increase the likelihood of adoption and continued use.
You create a positive first impression, encouraging users to explore your package further.
You reduce the support burden, as fewer users encounter installation issues.
Think back to the moment that you picked up someone else’s Python package
and it just worked… wasn’t that a magical feeling?
When you build a tool, you’ll want to get users to the “aha!” moment
of using your package as quickly and painlessly as possible.
Every step you can eliminate or simplify in the setup process
is a win for user adoption and satisfaction.
Key concept 3: Documentation as a bridge to understanding
Documentation is often treated as an afterthought in data science projects,
but it’s a crucial bridge between your code and its users.
Good documentation can make the difference
between a project that gathers dust
and one that becomes widely adopted and built upon.
The Diataxis framework,
developed by Daniele Procida,
provides an excellent structure
for thinking about and organizing documentation.
The role of documentation
The Diataxis framework identifies four distinct types of documentation, each serving a specific purpose:
Tutorials: Learning-oriented guides that help new users get started quickly.
How-To Guides: Problem-oriented instructions for completing specific tasks.
Explanation: Understanding-oriented discussions that provide background and context.
Reference: Information-oriented technical descriptions of the code.
These four types of documentation serve different roles in a user’s journey:
Onboarding: Tutorials help new users quickly understand and start using your code.
Problem-Solving: How-To Guides assist users in accomplishing specific tasks.
Deep Understanding: Explanation sections provide insight into the why and how of your project.
Detailed Information: Reference documentation offers a reliable source of information for all features and functions.
Types of documentation artifacts
Within these four categories, you might create various documentation artifacts:
README: The first point of contact for users, providing an overview and quick start guide.
API Documentation: Detailed explanations of functions, classes, and modules (part of the Reference quadrant).
Tutorials: Step-by-step guides for common use cases (part of the Tutorials quadrant).
Examples: Practical demonstrations of how to use the code in real-world scenarios (often part of How-To Guides).
Inline Comments: Explanations within the code itself for complex logic or algorithms (can feed into Reference documentation).
By structuring your documentation according to the Diataxis framework,
you can ensure that you’re meeting the diverse needs of your users,
from newcomers to experienced developers looking for specific information.
Best practices for effective documentation
When it comes to creating effective documentation,
there are several key practices to keep in mind.
Contemporaneous documentation:
First and foremost,
it’s crucial to write documentation as you code,
rather than leaving it as an afterthought!
Leaving just-in-time comments
can help you preserve critical details that may be handy
for future readers of your code.
This approach ensures that your documentation remains accurate and complete,
reflecting the most up-to-date state of your project.
Clear language:
Clear language is paramount in documentation.
Avoid using jargon or overly technical terms without explanation.
Instead, strive to explain complex concepts in simple, accessible language
that a wide range of users can understand.
This clarity helps reduce the learning curve for new users
and makes your project more approachable.
If you use tools like Quarto or MyST,
you can use pop-ups, sidebars, and callouts
to help disambiguate explain terms.
Examples:
Examples are a powerful tool in documentation.
Whenever possible,
include code snippets and use cases
that illustrate how to use your package.
These practical demonstrations can help users
quickly grasp how to apply your code to real-world scenarios,
bridging the gap between theory and practice.
Regular updates:
As your project evolves,
so should your documentation.
Regularly reviewing and updating your documentation
is essential to ensure it remains relevant and accurate.
This ongoing maintenance helps prevent confusion and frustration
that can arise from outdated or incorrect information.
Personally,
I’ve been building GenAI tooling
to help me identify out-of-date documentation
as my codebase evolves,
as well as update the documentation directly.
I’ve been prototyping this in LlamaBot,
and if you’re interested in talking about it,
I’m more than happy to chat!
Tooling:
Finally, consider leveraging documentation tools
to enhance the presentation and organization of your content.
Documentation systems, such as Quarto and MkDocs
can help you create professional-looking documentation
that’s easy to navigate and visually appealing.
These tools can significantly improve the user experience,
making your documentation more engaging and effective.
Additionally, use LLMs to help you draft documentation!
It’ll help you get over writer’s block.
The impact of good documentation
Investing in quality documentation yields far-reaching benefits for your data science project:
It increases user adoption and satisfaction
It reduces support burden on maintainers
It fosters a vibrant community by encouraging contributions
It enhances project credibility and professionalism
It maximizes code’s potential and impact
Remember, even the most brilliant code
is only as valuable as users’ ability to understand and implement it.
High-quality documentation is the key that unlocks your code’s full potential,
amplifying its reach and influence in the field.
By creating and maintaining excellent documentation,
you’re not just explaining your code –
you’re expanding its impact within the data science community and beyond.
How we operationalize these ideas at work
At Moderna, where I work,
I’ve been fortunate to be an early member of
the Data Science and Artificial Intelligence teams.
This gave me the opportunity to influence the ways of working
of a team that was still figuring out how to operationalize these ideas in practice.
We’ve implemented several concrete practices
that bring these concepts to life in our daily work.
Code reviews
One of our key practices is the consistent use of code reviews.
Except for rapid prototyping that needs to be completed within an afternoon,
we always conduct code reviews.
While this process may slow us down in the short term,
typically adding a day or two of waiting for colleagues to review,
it pays off significantly in the long run.
(Moreover, we use AI-assisted coding to speed up our code writing anyway,
so not much is lost!)
We move faster overall because of the growing shared knowledge across the team.
Code reviews are particularly crucial
for ensuring both the correctness and maintainability of our code.
They also serve as an excellent way for team members
to learn coding patterns from each other and maintain high code quality.
It’s worth noting that a hallmark of an experienced programmer
is their ability to deploy effective patterns in their codebase.
Docathons and AI-assisted documentation
We also emphasize the habit of writing documentation through regular “docathons.”
Every quarter, we set aside two days specifically for working on documentation.
During these events, we focus on updating documentation for our various projects.
These docathons serve a dual purpose:
they are not only productive work sessions but also great team-building exercises.
We find that newcomers to the team are particularly helpful during these events,
as they assist in keeping our onboarding documentation up to date,
providing fresh perspectives on what new team members need to know.
In addition, we use AI to help us draft documentation.
Modeling after documentation tooling that I built for LlamaBot,
we use the same pattern at work to help us draft documentation,
especially for routine, templated, and tedious-to-write documentation.
Humans are still responsible for checking the drafted documentation,
but at least we use AI tools to help us get started.
Standard project templates and automation
To streamline our development process,
we have implemented standard project templates and automation tools.
Our approach is similar to Cookiecutter Data Science-templated projects,
but with additional automation and customization specific to Moderna’s needs.
We make extensive use of pre-commit hooks and GitHub Actions
to automatically check our code with every commit.
This automation significantly alleviates
the mental burden associated with manual checking.
By leveraging these tools,
we have effectively removed much of the human burden
typically associated with nitpicking another person’s code.
Instead, we let the automated systems handle these checks,
and we simply respond to what the “robots” tell us needs attention.
The impact of these practices
Through these practices,
we have created an environment where clean, distributable,
and well-documented code is not just an ideal,
but a daily reality.
This approach has significantly enhanced our team’s efficiency,
collaboration, and the overall quality of our data science projects at Moderna.
We engage in long-term research partnerships with our colleagues
and can reliably take code from prototype to production with minimal overhead.
We easily onboard new people onto projects
thanks to the high-quality documentation provided.
Conclusion
Throughout this keynote blog post,
we’ve explored the critical human dimension of data science code,
focusing on three key concepts:
readability, user-friendly installation, and documentation.
These elements,
often overlooked in favor of algorithmic efficiency or cutting-edge techniques,
are fundamental to the success and impact of your data science projects.
Readability reduces cognitive load and fosters collaboration,
inviting others to build upon our work.
This openness drives scientific progress in data science.
User-friendly installation lowers barriers to entry,
encouraging wider adoption and increasing impact.
A brilliant but unusable algorithm is effectively useless.
Documentation bridges code and users,
serving as a form of communication and teaching.
Good documentation can transform users into contributors,
fostering a community around your project.
These practices are fundamental to open science and reproducible research.
By making our code accessible and understandable,
we enable verification, replication, and advancement of scientific work.
This approach addresses the reproducibility crisis in many fields.
Ultimately, we contribute to a more transparent and robust scientific ecosystem,
not just improving individual projects.
As data scientists, our goals are to create tools and analyses that make a real-world impact.
By considering the human dimension to how our code gets used,
we dramatically increase the chances of our work being used,
understood, and built upon by others.
As you go forward, be other-centered in your work,
and treat your customers as you would want them to treat you!
Call to action
As you embark on your next data science project, challenge yourself to:
Prioritize readability from the start.
Create a smooth installation process.
Document as you go, not as an afterthought.
Seek early user feedback.
Contribute to open-source projects, focusing on documentation and user experience.
Impactful data science isn’t just about clever algorithms or big data.
By adopting a toolmaker’s mindset,
we create knowledge that others can easily access, understand, and build upon.
This approach enhances our ability to solve real-world problems creatively.
Let’s commit to writing code that’s both computationally efficient and human-friendly.
In doing so, we’ll foster a more collaborative, innovative, and impactful data science community.
Thank you for reading!
Detailed explanation of the documentation framework mentioned in this post.
FAQ
Should I be using AI tools to help me code?
Yes! And make sure you are ready to defend every line of code that is produced by an AI tool.
My personal conviction is that humans who write with AI assistance
will be the ones who are able to turbocharge their effectiveness.
At the same time, humans are the ones who are responsible for the end product.
So, let AI assist you, but don’t relinquish your responsibility!
Should I be using AI tools to help me write my documentation?
Yes! And just like with code,
make sure you are ready to defend every line of documentation that is produced by an AI tool.
In fact, I wrote this blog post with the help of Claude 3.5 Sonnet,
in which I drafted out my ideas in bullet point format
and then asked Claude to help me flesh out each section one at a time
into a cohesive written piece.
And I’m ready to defend every line that’s in this blog post
or else be willingly corrected!
What if I don’t have time to write documentation?
Use AI tools to help!
But if you’re in an airgapped environment with no access to AI tools over an API,
see if you’re able to procure hardware to run local LLMs on your own machine.
It turns out that we have supercomputers (by 1980s standards) in our pockets,
on our laps, and on our desks,
and the total amount of compute capacity that just runs idle is staggering.
]]>Eric J. MapyOpenSci celebrates Inessa Pawson2024-10-10T00:00:00+00:002024-10-10T00:00:00+00:00https://www.pyopensci.org/blog/pyOpenSci-celebrates-Inessa-pawsonpyOpenSci Celebrates Inessa
Today, I want to take a moment to celebrate a devoted pyOpenSci community member, colleague, and friend, Inessa,
who was just awarded the NumFOCUS Community Leadership award. In my opinion, no one is more deserving of recognition for their contributions and dedication
to the open source community. Inessa’s day job at OpenTeams is devoted to open source, where she serves as the Open Source Program
Manager. But her open source work extends far beyond her professional role!
Inessa receives the 2024 NumFOCUS Community Leadership award.
“Inessa Pawson receives the NumFOCUS Community Leadership Award 2024. Inessa, a pyOpenSci Advisory Council member, is celebrated for her impact in the scientific Python
community, including co-organizing the SciPy US and PyCon US Maintainers Summits, serving on the NumPy Steering Council, and leading a number of contributor
experience projects.”
I have tremendous admiration for Inessa’s commitment to supporting the open source community, particularly in the scientific Python ecosystem. Her efforts reach
far beyond pyOpenSci, impacting the broader open science and Python landscapes.
Inessa’s open source contributions
To foster opportunities for cross-project collaboration in open source and open science, Inessa has co-organized the SciPy US conference
since 2020, establishing and serving on several committees (Maintainers Track, Teen Track, Tutorials, Social Activities, Mentorship Program, Hybrid Committee). She has
also organized the NumFOCUS Project Summit for the past two years (2023 and 2024) and serves on the Scientific Python Project SPEC Steering Committee.
Inessa has championed the NumFOCUS Code of Conduct (CoC) reform and the creation of the NumFOCUS CoC Working Group.
Inessa is also a core contributor to the scientific Python community. Amongst many commitments within the scientific Python ecosystem, she has been serving
on the NumPy Steering Council since 2021 and co-leading the scikit-learn survey team since early 2024. Inessa is a recipient of the 2019 NumPy
New Contributor Award.
What truly sets Inessa apart is her relentless commitment to community building. She is a founder and organizer of the CHAOSS Scientific Research Working Group,
Tech Alliance of SWFL, PyLadies South Florida, and PySWFL (Python user group in SWFL). Inessa doesn’t just participate; she builds frameworks and fosters connections
to ensure the sustainability of the communities that fuel scientific progress.
Inessa cares about DEIA - deeply
Inessa’s leadership and passion for fostering inclusive, supportive communities also extend to her role on the pyOpenSci Advisory Council. She has always been
there to talk through challenges as pyOpenSci has grown over the years. I see her as a key advisor behind pyOpenSci’s success.
Inessa is also a devoted mom
On top of all these accomplishments, Inessa is a dedicated mother to two wonderful, bright children who you may have run into at a PyCon US or SciPy US conference!
And, on a personal note, Inessa is a wonderful friend and an incredible human being. I can’t think of anyone more deserving of recognition.
Her wide-ranging contributions make her a true leader in the open source community. I’m so happy to be able to take a moment to celebrate her impact.